http://linux.cn/article-4326-1.html
iproute2 对决 net-tools
| 如今很多系统管理员依然通过组合使用诸如ifconfig、route、arp和netstat等命令行工具(统称为net-tools)来配置网络功能,解决网络故障。net-tools起源于BSD的TCP/IP工具箱,后来成为老版本Linux内核中配置网络功能的工具。但自2001年起,Linux社区已经对其停止维护。同时,一些Linux发行版比如Arch Linux和CentOS/RHEL 7则已经完全抛弃了net-tools,只支持iproute2。 作为网络配置工具的一份子,iproute2的出现旨在从功能上取代net-tools。net-tools通过procfs(/proc)和ioctl系统调用去访问和改变内核网络配置,而iproute2则通过netlink套接字接口与内核通讯。抛开性能而言,iproute2的用户接口比net-tools显得更加直观。比如,各种网络资源(如link、IP地址、路由和隧道等)均使用合适的对象抽象去定义,使得用户可使用一致的语法去管理不同的对象。更重要的是,到目前为止,iproute2仍处在持续开发中。 如果你仍在使用net-tools,而且尤其需要跟上新版Linux内核中的最新最重要的网络特性的话,那么是时候转到iproute2的阵营了。原因就在于使用iproute2可以做很多net-tools无法做到的事情。 对于那些想要转到使用iproute2的用户,有必要了解下面有关net-tools和iproute2的众多对比。
显示所有已连接的网络接口下面的命令显示出所有可用网络接口的列表(无论接口是否激活)。 使用net-tools:
使用iproute2:
激活或停用网络接口使用这些命令来激活或停用某个指定的网络接口。 使用net-tools:
使用iproute2:
为网络接口分配IPv4地址使用这些命令配置网络接口的IPv4地址。 使用net-tools:
使用iproute2:
值得注意的是,可以使用iproute2给同一个接口分配多个IP地址,ifconfig则无法这么做。使用ifconfig的变通方案是使用IP别名。
移除网络接口的IPv4地址就IP地址的移除而言,除了给接口分配全0地址外,net-tools没有提供任何合适的方法来移除网络接口的IPv4地址。相反,iproute2则能很好地完全。 使用net-tools:
使用iproute2:
显示网络接口的IPv4地址按照如下操作可查看某个指定网络接口的IPv4地址。 使用net-tools:
使用iproute2:
同样,如果接口分配了多个IP地址,iproute2会显示出所有地址,而net-tools只能显示一个IP地址。
为网络接口分配IPv6地址使用这些命令为网络接口添加IPv6地址。net-tools和iproute2都允许用户为一个接口添加多个IPv6地址。 使用net-tools:
使用iproute2:
显示网络接口的IPv6地址按照如下操作可显示某个指定网络接口的IPv6地址。net-tools和iproute2都可以显示出所有已分配的IPv6地址。 使用net-tools:
使用iproute2:
移除网络设备的IPv6地址使用这些命令可移除接口中不必要的IPv6地址。 使用net-tools:
使用iproute2:
改变网络接口的MAC地址使用下面的命令可篡改网络接口的MAC地址,请注意在更改MAC地址前,需要停用接口。 使用net-tools:
使用iproute2:
查看IP路由表net-tools中有两个选择来显示内核的IP路由表:route和netstat。在iproute2中,使用命令ip route。 使用net-tools:
使用iproute2:
添加和修改默认路由这里的命令用来添加或修改内核IP路由表中的默认路由规则。请注意在net-tools中可通过添加新的默认路由、删除旧的默认路由来实现修改默认路由。在iproute2使用ip route命令来代替。 使用net-tools:
使用iproute2:
添加和移除静态路由使用下面命令添加或移除一个静态路由。 使用net-tools:
使用iproute2:
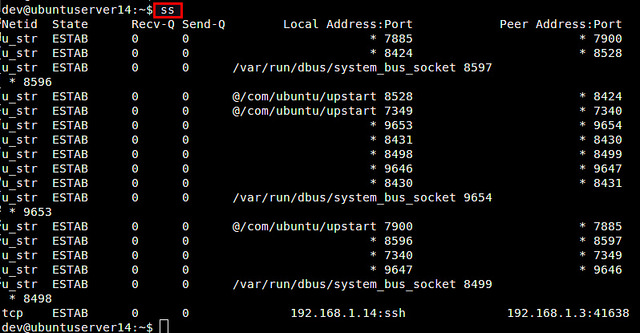
查看套接字统计信息这里的命令用来查看套接字统计信息(比如活跃或监听状态的TCP/UDP套接字)。 使用net-tools:
使用iproute2:
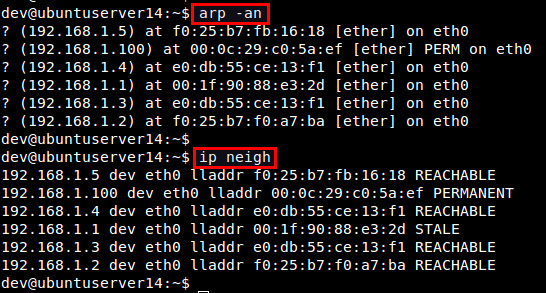
查看ARP表使用这些命令显示内核的ARP表。 使用net-tools:
使用iproute2:
添加或删除静态ARP项按照如下操作在本地ARP表中添加或删除一个静态ARP项。 使用net-tools:
使用iproute2:
添加、删除或查看多播地址使用下面的命令配置或查看网络接口上的多播地址。 使用net-tools:
使用iproute2:
via: http://xmodulo.com/2014/09/linux-tcpip-networking-net-tools-iproute2.html 作者:Dan Nanni 译者:KayGuoWhu 校对:wxy 本文由 LCTT 原创翻译,Linux中国 荣誉推出 原文:http://xmodulo.com/2014/09/linux-tcpip-networking-net-tools-iproute2.html作者: Dan Nanni |
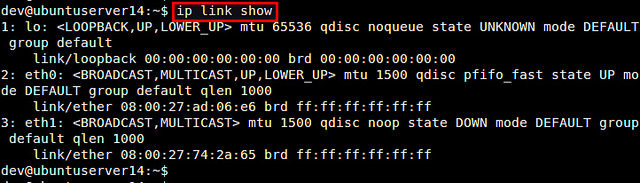
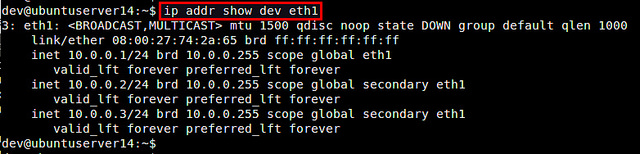
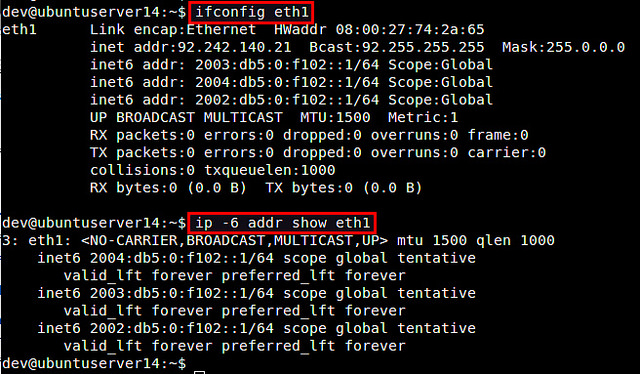
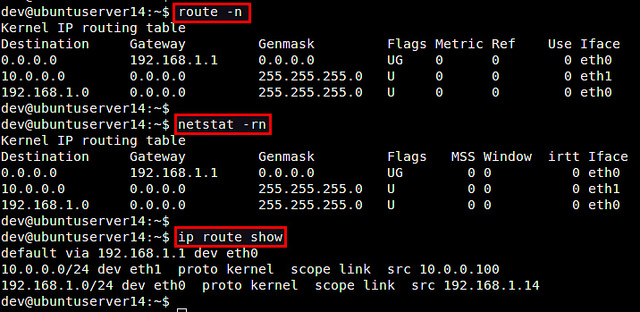
linux 高级路由
1. 什么是高级路由?是把信息从源穿过网络到达目的地的行为. 有两个动作:确定最佳路径,传输信息确定最佳路径:手工指定,自动学习。 传输信息:隧道传输,流量整形高级路由(策略路由)是根据一定的需要定下一些策略为依据。rpdb(routing policy data base)通过一定的规则进行路由 2.什么是多路由表及规则? (1) 多路由表用来等待匹配,默认有四张路由表 255 是本地路由表 254 主路由表 没有指明表所属位置 都放在这里 253 默认路由表 0 系统保留的表(2)规则 rpdb可以匹配数据包的源地址 目的地址 进入接口 每一个路由 动作 选择下一跳地址, 产生通讯时被 3.ip ip link show 显示所有的网络设备 ip address show ip route show table 255 显示指定编号的表 ip rule 定义规则 ip rule add from 192.168.2.1/32 table 1 从192.168.2.1的包按照1的表进行匹配 ip rule show 显示规则 ip rule add from 192.168.2.1/24 pref 1000 prohibit 从192.168.2.1的包返回不可达 ip rule del pref 32764 删除规则 ip route add 192.168.2.0/24 via 202.96.156.111 table 1 访问外网例如 ip rule add 192.168.2.1 table 1 pref 1000 ip rule add 192.168.2.2 table 1 pref 1005 ip rule add 192.168.2.3 table 1 pref 1010 ip rule add 192.168.2.0/24 table 2 pref 1015 ip route add 192.168.2.0/24 via 2M table 1 ip route add 192.168.2.0/24 via 1M table 2 ip route add default via 192.168.1.1 table 2 proto statc 设置默认网关 (ip route flush cache 刷新表1的缓存) ip route flush table 1 清空表负载均衡 1M 2M ip route add default scope global nexthop via ip1 dev eth0 weight 1 nexthop via ip2 dev eth1 weight 1 第一跳eth0 第二跳eth1 第三跳 eth0 。。。。。。。。 ip route add default scope global nexthop via ip1 dev eth0 weight 2 nexthop via ip2 dev eth1 weight 1 第一跳eth0分2/3 第二条eth1 1/3 实验 有三种人老板 美眉 我 员工4.IP 隧道 (ip-ip) 一层 ip-ip 二层 GRE 三层 ipsec {加密(ESP),认证(AH),协商(IKE)} 隧道模式 主机包头--AH--ESP--数据 传输模式 安全网关头部--AH--ESP--主机头|数据 (VPN) NtoN 虚拟处于一个局域网中解释1.qdisc 队列2.pfifo_fast (先进先出)有3个频道 priomap:3.(1)令牌桶过滤器 (tbf) 数据流=令牌流 无延迟的通过队列 数据流 <令牌流 消耗一部分令牌 剩下的在桶里积累,直到桶被填满,剩下的会在令牌> 数据的时候消耗掉 数据流>令牌流 导致tbf中断一断时间 发生丢包现象 (2)使用 limit/latency 最多有多少数据在队列中等待可用的令牌/确定了一个包在tbf中等待传输的最长等待时间 burst/buffer/maxburst 桶的大小 (字节) 10M bit/s的速率---10k字节 mpu 令牌的最低消耗 (0长度的包需要消耗64字节的带宽) rate 速度操纵4.实验 tc qdisc add dev eth0 root tbf rate 220kbit latency 50ms burst 1540 将网卡设备eth0加入队列中,以root为根的令牌桶,数据不超过220k速率通过,当数据包等待50ms没有拿到令牌 则丢弃,定义桶的大小为1540字节5.随机公平队列 (sfq) 解释:将流量分为相当多的FIFO队列中 每个队列对应一个会话数据按照简单轮转方式发送,每个会话都按顺序得到发送机会 解决问题:网络阻塞 参数:1.perturb 多少秒重新配置一次散列算法,一般为10m 2.quantum 一个流要传输多少字节后才切换到下个队列 一般设为一个包的最大长度6.tc qdisc add dev ppp0 root sfq perturb 107.队列的选取 降低出口速率 令牌桶过滤器 链路已经塞满,想保证不会有某一个会话独占出口带宽, 使用随机公平队列 有一个很大的骨干带宽, 随机丢包 希望对入口流量整形 入口流量整形8.分类的队列规定 cbq 实验 要求:总体的网络布局,有三种人 学生 教师 教职员工,1.学生:每栋宿舍分10m带宽 需要流量整形,学生不和教职员工的网络连接,不可以访问外部网络,可以访问学校内部的FTP 和视频点播服务器2.教师:共享10m带宽,教师的网络和教职员工的网络连通 可以访问学校的FTP 视频点播 web服务器3.教职员工:共享1 0m带宽,可以访问学校内部的web服务器 不能访问FTP 和视频点播服务器:web服务器用来提供erp 有一个站点 用来提供资料下载,ftp服务器 保存各种视频资料,视频课件 ,视频点播服务器:提供教师学生视频 娱乐 外部的web服务器。学校的主站 学校内部有四个网络机房,平时上课用来做实验 晚上用来上网,四个机房共享100m带宽。网络安全,外部不能访问内部的视频 ftp服务器。注意防止改变ip地址获得其他角色的服务。希望有一套机制监控全校的网络使用状况~new~ppp的包rp-pppoe-3.5-32.1ppp-2.4.4-1.el5/etc/ppp/pppoe-server-options (options)验证方式pap pap-secrets(不可用)chap chap-secrets man pppdvim pppoe-server-options# PPP options for the PPPoE server# LIC: GPLrequire-chaploginlcp-echo-interval 10lcp-echo-failure 2ms-dns 192.168.0.22 给客户端logfile /var/log/pppoe.logvim chap-secrets# Secrets for authentication using CHAP# client server secret IP addresses####### redhat-config-network will overwrite this part!!! (begin) ##########joker * 123456 *tom * 123456 *jerry * 123456 *shrek * 123456 *####### redhat-config-network will overwrite this part!!! (end) ############uname -r rhel5 u1 u2 service syslog stop 有bug,u3没有bugpppoe-service -I eth0 -L 172.16.0.1 -R 10.0.0.1 -N 100 服务器地址 客户端地址池客户端adsl-setupadsl-startadsl-stoptc 流量控制 sfq tbfCLASSFUL QDISCSHTB 分层令牌桶PRIO tc class ls dev eth0tc qd add dev eth0 root priotc qd add dev eth0 parent 8016:1 tbf rate 10kbit limit 5k burst 5ktc qd add dev eth0 parent 8016:2 sfqtc qd add dev eth0 parent 8016:3 sfq tc qd lsqdisc pfifo_fast 0: dev eth1 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1tc qd add dev eth0 root sfqtc qd del dev eth0 root sfqtc qd add dev eth0 root pfifotc qd add dev eth0 root tbf rate 256kbit limit 10k burst 10ktc qd add dev eth0 root handle 1: tbf rate 256kbit limit 10k burst 10k1:0 1:2 ......高级路由pppoe点到点协议利用pppoe可防止arp欺骗adsl-setup这是拨号上网的命令radius的记帐服务器 AAA协议安装包:rpm -ivh pp-2.4.4.... rp-pppoe-3.5-32.1cd /etc/pppvim pppoe-servar身份验证方式:chap-secretspap-secrets不能用修改---------require-chaploginlcp-echo-interval 10密码身份验证lcp-echo-railure 2以下为添加:ms-dns 192.168.0.254此处为dns地址logfile /var/log/pppo.log日志路径-----------------man pppd查看可添加的配置参数-----------------创建帐户和密码vim chap-secretszorro * 123456(密码明文) *(可分配的ip,要在地址段内)----------------查版本:uname -rrhel5 u1 u2之间是冲突的service syslog stop 关闭日志:这是必需的-------------------设置网卡监听pppoe-server -I eht0 -L(指定虚ip.登录后可见到的ip)172.16.0.1-R(分给客户端的ip)10.0.0.1-N 100(个数是100个)----------------------客户端拨号adsl-setup1eth0(哪个网卡连接的就用哪个网卡建)2name:aorro3网卡:eth04dns:5passwd:6是否允许一般用户启动:7防火墙规则:09是否保存设置:---------启动拨号:adsl-start中断拨号:adsl-stop-------------客户间通信是要通过服务器的****************-------------------查看日志:tail -f /var/log/pppoe.log记录登录目录服务器设置的用户名才能能真正登录的-----------------------设置记帐:时间记帐:的对话叫:aaloth-up;实际的ip连接:ip-up;退出过程:aloth-down;(这个时间是记帐的最好时间)数据包量查看:(流量记帐)netstat -i------------为记帐建立脚本:vim /auth-up#!/bin/bashexport LANG=Cecho $PEERNAME login at 'date' >> /tmp/pppd-login.log这是帐户登录的时间-----vim /auth-down#!/bin/bashLANG=Cecho $PEERNAME logout in 'date' >> /tmp/pppd-loging.log这是帐户登出的时间---------kilkall -9cat /tmp/pppd-login.log-----------怎样限制客户端的速度:客户端下行速度,在服务器端限制是上行速度。tc命令:网卡:tcssh 10.0.0.93服务器端限制上行速度:tc qdisc add dev ppp1 root tbf rate 256kbit limit 10k burst 10k 这是对ppp1的上行速度做的限制重启服务:service httpd restart去掉限速:add>>del-------------自动设置限速:vim /etc/ppp/ip-up[ -x /etc/ppp/ip-up.local ] && /etc/ppp/ip-up.local "$@"下面加入:设置vip同帐户if [ $PEERNAME = " zorro"]then tc qdisc add dev $IFNAME root tbf rate 512kbit limit 10k burst 10k exit 0fitc qdisc add dev $IFNAME root tbf rate 512kbit limit 10k burst 10k查看:tc qdisc listkailkill -9 pppdip ad sh************************---------------------------tc交通控制:OBJECT:1 qdisc:队列规则;队列的优先级依次排列,前面比后面的高[0.1.2共计16个,不同的位标记为不同的队列:一般服务排在中间队列。]。2class:3filter:4action:5monitor:tc qd 显示当前所有队列规则:qdisc pfifo_fast 0: dev eth0 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 10000:1 0001:20010:2 0011:2这个队列规则为pfifo_fastman tc 两大类:不可分类;CLASSLESS QDISCS1 [p|b]fifo2 pfifo_fast3 red随机优先4 sfq完全公平5 tbf没有所谓的队列,相当只有一个队列,令牌总队列。每一个会话连接称为:session 完全公平默认是tc qd tc qd add dev eth0 root sfq修改默认队列规则tcqd del dev etho root sfq 删除队列规则tc qd add dev eth0 root pfifo添加规则tc qd add dev eth0 root tbf rate 256kbit (limit 10 <burst 10令牌总的参数>) 附属参数[添加规则时必须加参数,不然会报错]8015:此外为编号,可指定加tc qd add dev eth0 root handle 1: (不加数字,默认为0)tbf rate 256kbit limit 10 burst 10网卡上行限速 tbf--------------分分类队列规则:CBQ:在高端应用广,软件上做即时限速是不准确的。软件上不适用。HTB:分层令牌总PRIO:tc qd add dev eth0 root prio区别是分类了tc class ls dev eth0 查验,默认产生3个类,还是以tos值分。8016:1、2、3,各有不同的优先级,类下可再加队列规则:要指定具体父类tc qd add dev eth0 parent 8016:1 tbf rate 10kbit limit 5k burst 5ktc qd add dev eth0 parent 8016:2 sfq tc qd add dev eth0 parent 8016:3 sfq----------------人为方式指定,而不是tos值。tc qd del dev etho roottc qd add dev eth0 root handle 1:priotc cl ls dev eth0查看tc qd add dev eth0 parent 1:1 tbf rate 256kbit burst 200k(字节)limit 10k tc qd add dev eth0 parent 1:2 tbf rate 5mbit burst 3m limit 10ktc qd add dev eth0 parent 1:3 tbf rate 1mbit burst 1mlimit 10ktc qd add dev eth0 parent 1:protocol ip prio 1001 (优先级)u32(过滤器类型) match ip(报头)dst 192.168.0.120 flowid 1:1tc qd add dev eth0 parent 1:protocol ip prio 1001 (优先级)u32(过滤器类型) match ip(报头)dst 192.168.0.128 flowid 1:2tc qd add dev eth0 parent 1:protocol ip prio 1001 (优先级)u32(过滤器类型) match ip(报头)dst 192.168.0.0/24 flowid 1:3其他人共享1m带宽{这就是分组处理}这是ip限制。环境:10m带宽,scp ssh smtp http 规定流量:scp10k;http5m,无其他人时10m;smtp5mman tc8pro实现-------------history 删除数字::1,$s/^ .... *\(tc.*$)/\1/g-----------脚本1vim #!/bin/bashwget http://192.168.0.254:/var/ftp/ki...._________________________建立文件:dd it=/dev/zer of=/varftp/bigfile________________________tc qd ls查看路径:man pppd在SCRIPTS中可看到相应的参数提示#双线路由切换rpm -q iproute iproute-2.6.18-4.el5ip address show dev eth0ip ad sh dev eth1[root@localhost ~]# ipUsage: ip [ OPTIONS ] OBJECT { COMMAND | help } ip [ -force ] [-batch filenamewhere OBJECT := { link | addr | route | rule | neigh | ntable | tunnel | maddr | mroute | monitor | xfrm } OPTIONS := { -V[ersion] | -s[tatistics] | -r[esolve] | -f[amily] { inet | inet6 | ipx | dnet | link } | -o[neline] | -t[imestamp] }ip link ,ip li sh,ip li help,[root@localhost ~]# ip ad add dev eth1 192.168.5.3/24[root@localhost ~]# ip ad sh dev eth1[root@localhost ~]# ip ad del dev eth1 192.168.5.3/24[root@localhost ~]# ip ne sh //看arp,[root@localhost ~]# ip ne helpUsage: ip neigh { add | del | change | replace } { ADDR [ lladdr LLADDR ] [ nud { permanent | noarp | stale | reachable } ] | proxy ADDR } [ dev DEV ] ip neigh {show|flush} [ to PREFIX ] [ dev DEV ] [ nud STATE ][root@localhost ~]# ip route sh ,ip ro ship ro add 10.0.0.1/32 dev eth1 ,route add -host 10.0.0.1 dev eth1ip ro del 10.0.0.1/32 dev eth1ip ro ship ro add default dev eth0 via 192.168.0.1ss -antp*ip ro del defaultip ro default dev nexthop dev eth0 via 211.0.0.1 weight 10 nexthop dev eth1 via 123.112.0.1 weight 5ip ro sh如果通过服务器上网,服务器做的是默认路由。vim root#!/bin/bashIFNAME1=eth0IFNAME2=ETH1IP1=211.0.01IP2=123.112.0.1while :do route del default route add default dev $IFNAME1 gw $IP1 while ping -c 1 211.0.0.1 & /dev/null do sleep 1 done route del default route add default dev $IFNAME2 gw $IP2 until ping -c 1 211.0.0.1 & /dev/null do sleep 1 donedone这是互备的内容----------------------------改变需求:两条线同时上网,默认路由是支持一条路由的,不能同时支持二条cd /usr/src/linux-2.6..make menuconfigIP:equal cost multipath选中------------------以上为填加高级路由必须操作的 rpm -q iproute 这是支持高级路由的包ifconfigroute -n netstat ip address show dev eth0显示eth0的网卡地址ip ad sh dev eth0同上命令,这是简写命令-------一定要查看以上命令ip 回车是命令参数ip link只针对三层ip ad 所有网卡显示ip ad add dev eth0 192.168.1.254/24这是填加ipip ad sh dev etho这是立即生效的ipconfig是看不见的ip ad del dev eth0 192.168.0.254/24这是删除编辑ip ad sh dev eth0显示链路层ip li ip li help帮助--------------------查看arp协议ip ne sh相当于:arp -nip ne help帮助ip rout sh 查看路由ip ro sh同上ip ro add 10.0.0.1/32 dev eth1添加路由 发往ip的包由eth1发出route add -host 10.0.0.1 dev eth1ip ro del 10.0.0.1/32 dev eth1ip ro add 100.0.0/8 dev eth0ip ro sh ip ro del 10.0.0.0/8 dev eth0ip ro del defaultip ro add default dev eth0 via 192.168.0.1ip ro shss -antpip ro add default dev eth0 via 192.168.0.1-----------添加ecmpip ro del defaultip ro add default dev eth0 via 211.0.0.1这是加一个加二个,后面加:ip ro add default nexthop dev eth0 via 211.0.0.1 nexthop dev eth1 via 123.112.0.1注意参数加权重:ip ro add default nexthop dev eth0 via 211.0.0.1 weight 10 nexthop dev eth1 via 123.112.0.1 weight5ip ro add default nexthop dev eth0 via 192.168.0.1 weight 10 nexthop dev eth1 via 192.168.1.2 weight 5ip ro sh 这是查看------------ecmp支持的问题脚本:vim ar_ecmp.sh#!/bin/bashIFNAME=eth0IPNAME=eth1IFNAME=eth2#........#IFNAME=ethnIP1=192.168.1.1IP2=192.168.1.2IP3=192.168.1.3#.......#IPn=xxx.xxx.xxx.xxxip ro del defaultip ro add default nexthop dev $IFNAME1 via $IP1 seight 1 \ nexthop dev $IFNAME2 via $IP2 seight 1 \ nexthop dev $IFNAME3 via $IP3 seight 1 #\# .......-------------以上为ecmp高级路由:部分上网走10m,部分走1mip ro sh table local这是所有经过本机的路由表ip ro sh table all 这是本机所有的路由表策略表:rule表,指定如何查其他表,匹配规则,这是路由的策略机制。可在策略这查ip经过的路由表可在策略表中指定ip范围所经过的带宽ip ro sh显示当前;默认路由cd /etc/vim rt_tables#reserved values255 local254 main253 unspec111 ta2101 ta1 添加时要按顺序##local ip ro sh ta 254ip ro sh ta ta1ip ro sh ta ta2以上两表添加相应的路由ip ro add 192.168.0.0/24 dev eth1 ta ta1ip ro add 192.168.1.0/24 dev eth1 ta ta1ip ro sh ta ta1ip ro del 192.168.0.0/24 dev eth1 ta ta1ip ro add 192.168.0.0/24 dev eth0 ta ta1ip ro sh ta ta1ip ro add default dev eth0 via 192.168.0.1 ta ta1ip ro sh ta ta1ip ro add 192.168.0.0/24 dev eth0 ta ta2ip ro add 192.168.1.0/24 dev eth1 ta ta2ip ro add default dev eth1 via 192.168.1.1 ta ta2ip ro sh ta ta2ip ro sh ta ta1设置策略,如何查表ip rule show[root@www ~]# ip rule show0: from all lookup 255 32766: from all lookup main 32767: from all lookup default You have new mail in /var/spool/mail/root顺序从上至下查表加规则:不同网段查不同表1~100查1表,101~253查2表ip ru(route) help帮助ip ru add from 192.168.0.1 ta ta1for i in 'seq 2 100';do ip ru add from 192.168.0.$i ta t1;donefor i in 'seq 2 253';do ip ru add from 192.168.0.$i ta t2;doneip ru show删除:for in in 'seq 1 253';do ip rou del from 192.168.0.$i;doneip ru sh_____________更换查找方式防火墙和高级路由联用:iptables -t mangle -A PREROUTING -m iprange --src-range 192.168.0.1-192.168.0.100 -j MARK --set-mark 1iptables -t mangle -A PREROUTING -m iprange --src-range 192.168.0.101-192.168.0.253 -j MARK --set-mark 2ip ru helpip ru add fwmark 1 ta ta1ip ru add rwmark 2 ta ta2ip ru sh -----------TC联用---------这是不同原地址发的带宽不一样---------------定义默认规则:ip ro sh 默认def表:ip ro sh ip ro sh ta ta1vim /etc/iproute2/rt_ip ro sh ta ta1ip ru ship ru del fwmark 2ip ru del fwmark 1ip ru sh ip ru add to 211.0.0.1 ta ta1ip ru sh根据目标地址指定以上防火墙添加标记ip ru help---------------要掌握结构ab测试ab -c 100 -n 1000 http://192.168.0.254vmstat 1renice -20 ?ps ax |grep httpdps ax |grep /usr/sbin/bttp |sed "$d' |awk ‘{print $1}';do renice -20 $i;donefor i in 'ps ax|grep /usr/sbin/httpd |sed '************************************vim #!/bin/bashcount=""ret=0for ((count=1000;count<=3000;count++))do for ((i=2;i Linux下双网接入高级路由配置脚本zz
#!/bin/bash IP0= IP1= GW0= GW1= NET0= NET1= DEV0=eth0 DEV1=eth1 # comment the next two line after first run this script. echo 200 cernet >>/etc/iproute2/rt_tables echo 210 chinanet >>/etc/iproute2/rt_tables ip route add ${NET0} dev ${DEV0} src ${IP0} table cernet ip route add default via ${GW0} table cernet ip route add ${NET1} dev ${DEV1} src ${IP1} table chinanet ip route add default via ${GW1} table chinanet ip route add ${NET0} dev ${DEV0} src ${IP0} ip route add ${NET1} dev ${DEV1} src ${IP1} # delete old rule ip rule del from ${IP0} ip rule del from ${IP1} # setup new rule ip rule add from ${IP0} table cernet ip rule add from ${IP1} table chinanet http://jpuyy.com/2014/01/ip-rule-and-ip-route.html ip rule和 ip route
相对ip route ,ip rule是高级路由,能实现不同条件路由的转发。
linux系统维护了路由表,用ip rule show可以查看路由表。
# ip rule show0: from all lookup local 32766: from all lookup main 32767: from all lookup default
路由表记录在/etc/iproute2/rt_tables文件中,默认里面会用这么几行,在这个文件里添加的路由表即时生效
255 local254 main253 default0 unspec
所以自定义一个路由表的时候,序号要在1-252之间,路由选择的优先级也与数字的大小有关,越小的优先级越高,先匹配。
数字后面要规定一个别名,方便使用和辨认。这样路由表的查看可有以下两种方法:
ip route list table table_numberip route list table table_name
如查看默认路由表可用如下命令
ip route list table mainip route list table 254
路由表添加完之后,接下来就是对路由表的操作,如果我有
eth1 配置ip 192.168.1.8/24 路由表 101 mytable1
eth2 配置ip 192.168.2.8/24 路由表 102 mytable2
不同段的从不同的网卡走。
ip route add 192.168.1.0 dev eth1 src 192.168.1.8 table mytable1ip route add default via 192.168.1.1 table mytable1ip rule add from 192.168.1.8 table mytable1ip route add 192.168.2.0 dev eth2 src 192.168.2.8 table mytable2ip route add default via 192.168.2.1 table mytable2ip rule add from 192.168.2.8 table mytable2
现在使用ip rule show查看
# ip rule show 0: from all lookup local 32764: from 192.168.2.8 lookup mytable2 32765: from 192.168.1.8 lookup mytable1 32766: from all lookup main 32767: from all lookup default
这时要删除rule可使用
ip rule del prio 32764
ip rule还可以实现更高级的功能,比如根据ip目的地址,包大小来进行转发。
查看route -n flag
The flags
Following is the list of flags and their significance in the routing table :
U : This flag signifies that the route is up
G : This flag signifies that the route is to a gateway. If this flag is not present then we can say that the route is to a directly connected destinationH : This flag signifies that the route is to a host which means that the destination is a complete host address. If this flag is not present then it can be assumed that the route is to a network and destination would be a network address.D : This flag signifies that this route is created by a redirect.M : This flag signifies that this route is modified by a redirect.策略路由以及使用 ip route , ip rule , iptables 配置策略路由实例
目录(?)[+]
http://blog.sina.com.cn/s/blog_659b48590100n2q6.html
例:
-------------------------------------------------------------------------------------------------------------------------------------
ip rule 命令
linux 高级路由即基于策略的路由,比传统路由在功能上更强大,使用也更灵活,它不仅能够像传统路由一样,根据目的地址来转发数据,而且也能够根据报文大小、应用,协议或ip源地址来选择路由转发路径从而让系统管理员能轻松做到:
1、 管制某台计算机的带宽。2、 管制通向某台计算机的带宽3、 帮助你公平地共享带宽4、 保护你的网络不受DOS的攻击5、 保护你的Internet不受到你的客户的攻击6、 把多台服务器虚拟成一台,并进行负载均衡或者提高可用性7、 限制你的用户访问某些计算机8、 限制对你的计算机的访问9、 基于用户帐号、MAC地址、源IP地址、端口、QOS《TOS》、时间或者content等进行路由
一、高级路由的基础IP ROUTE2
基本命令:
linux系统路由表
linux可以自定义从1-252个路由表, linux系统维护了4个路由表: 0表 系统保留表高级路由重点之一路由规则 ip rule
进行路由时,根据路由规则来进行匹配,按优先级(pref)从低到高匹配,直到找到合适的规则,所以在应用中配置默认路由是必要的。 ip rule show 显示路由规则。 路由规则的添加: # ip rule add from 192.168.1.10/32 table 1 pref 100 如果pref值不指定,则将在已有规则最小序号前插入 注:创建完路由规则若需立即生效须执行route 命令
使用 Route 命令行工具查看并编辑计算机的 IP 路由表。Route 命令和语法如下所示:
route [-f] [-p] [Command [Destination] [mask Netmask] [Gateway] [metric Metric]] [if Interface]]-f 清除所有网关入口的路由表。 -p 与 add 命令一起使用时使路由具有永久性。 Command 指定您想运行的命令 (Add/Change/Delete/Print)。 Destination 指定该路由的网络目标。 mask Netmask 指定与网络目标相关的网络掩码(也被称作子网掩码)。 Gateway 指定网络目标定义的地址集和子网掩码可以到达的前进或下一跃点 IP 地址。 metric Metric 为路由指定一个整数成本值标(从 1 至 ArrayArrayArrayArray),当在路由表(与转发的数据包目标地址最匹配)的多个路由中进行选择时可以使用。 if Interface 为可以访问目标的接口指定接口索引。若要获得一个接口列表和它们相应的接口索引,使用 route print 命令的显示功能。可以使用十进制或十六进制值进行接口索引。 /? 在命令提示符处显示帮助。 示例:使用route 命令添加的路由,机器重启或者网卡重启后路由就失效了,方法:
//添加到主机的路由 # route add –host 192.168.168.110 dev eth0 # route add –host 192.168.168.119 gw 192.168.168.1 //添加到网络的路由 # route add –net IP netmask MASK eth0 # route add –net IP netmask MASK gw IP # route add –net IP/24 eth1 //添加默认网关 # route add default gw IP //删除路由 # route del –host 192.168.168.110 dev eth0添加一条路由(发往192.168.62这个网段的全部要经过网关192.168.1.1:
route add -net 192.168.62.0 netmask 255.255.255.0 gw 192.168.1.1 删除一条路由 route del -net 192.168.122.0 netmask 255.255.255.0 删除的时候不用写网关。 若要显示 IP 路由表的全部内容,请键入:# route printKernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface 10.147.9.0 * 255.255.255.0 U 1 0 0 eth0 192.168.1.0 * 255.255.255.0 U 2 0 0 wlan0 192.168.122.0 * 255.255.255.0 U 0 0 0 virbr0 link-local * 255.255.0.0 U 1000 0 0 eth0 192.168.0.0 192.168.1.1 255.255.0.0 UG 0 0 0 wlan0 default 10.147.9.1 0.0.0.0 UG 0 0 0 eth0 root@Ubuntu:~# 结果是自上而下, 就是说, 哪条在前面, 哪条就有优先, 前面都没有, 就用最后一条default。 若要显示以 10. 起始的 IP 路由表中的路由,请键入:route print 10.*若要添加带有 1Array2.168.12.1 默认网关地址的默认路由,请键入:route add 0.0.0.0 mask 0.0.0.0 1Array2.168.12.1若要向带有 255.255.0.0 子网掩码和 10.27.0.1 下一跃点地址的 10.41.0.0 目标中添加一个路由,请键入:route add 10.41.0.0 mask 255.255.0.0 10.27.0.1若要向带有 255.255.0.0 子网掩码和 10.27.0.1 下一跃点地址的 10.41.0.0 目标中添加一个永久路由,请键入:route -p add 10.41.0.0 mask 255.255.0.0 10.27.0.1若要向带有 255.255.0.0 子网掩码、10.27.0.1 下一跃点地址且其成本值标为 7 的 10.41.0.0 目标中添加一个路由,请键入:route add 10.41.0.0 mask 255.255.0.0 10.27.0.1 metric 7若要向带有 255.255.0.0 子网掩码、10.27.0.1 下一跃点地址且使用 0x3 接口索引的 10.41.0.0 目标中添加一个路由,请键入:route add 10.41.0.0 mask 255.255.0.0 10.27.0.1 if 0x3若要删除到带有 255.255.0.0 子网掩码的 10.41.0.0 目标的路由,请键入:route delete 10.41.0.0 mask 255.255.0.0若要删除以 10. 起始的 IP 路由表中的所有路由,请键入:route delete 10.*若要将带有 10.41.0.0 目标和 255.255.0.0 子网掩码的下一跃点地址从 10.27.0.1 修改为 10.27.0.25,请键入:route change 10.41.0.0 mask 255.255.0.0 10.27.0.25ip命令的语法
ip命令的用法如下: ip [OPTIONS] OBJECT [COMMAND [ARGUMENTS]] 4.1 ip link set--改变设备的属性. 缩写:set、s 示例1:up/down 起动/关闭设备。 # ip link set dev eth0 up 这个等于传统的 # ifconfig eth0 up(down) 示例2:改变设备传输队列的长度。 参数:txqueuelen NUMBER或者txqlen NUMBER # ip link set dev eth0 txqueuelen 100 示例3:改变网络设备MTU(最大传输单元)的值。 # ip link set dev eth0 mtu 1500 示例4: 修改网络设备的MAC地址。 参数: address LLADDRESS # ip link set dev eth0 address 00:01:4f:00:15:f1 4.2 ip link show--显示设备属性. 缩写:show、list、lst、sh、ls、l -s选项出现两次或者更多次,ip会输出更为详细的错误信息统计。 示例: # ip -s -s link ls eth0 eth0: mtu 1500 qdisc cbq qlen 100 link/ether 00:a0:cc:66:18:78 brd ff:ff:ff:ff:ff:ff RX: bytes packets errors dropped overrun mcast 2449949362 2786187 0 0 0 0 RX errors: length crc fifo missed 0 0 0 0 0 TX: bytes packets errors dropped carrier collsns 178558497 1783946 332 0 332 35172 TX errors: aborted fifo window heartbeat 0 0 0 332 这个命令等于传统的 ifconfig eth0 5.1 ip address add--添加一个新的协议地址. 缩写:add、a 示例1:为每个地址设置一个字符串作为标签。为了和Linux-2.0的网络别名兼容,这个字符串必须以设备名开头,接着一个冒号, # ip addr add local 192.168.4.1/28 brd + label eth0:1 dev eth0 示例2: 在以太网接口eth0上增加一个地址192.168.20.0,掩码长度为24位(155.155.155.0),标准广播地址,标签为eth0:Alias: # ip addr add 192.168.4.2/24 brd + dev eth1 label eth1:1 这个命令等于传统的: ifconfig eth1:1 192.168.4.2 5.2 ip address delete--删除一个协议地址. 缩写:delete、del、d # ip addr del 192.168.4.1/24 brd + dev eth0 label eth0:Alias1 5.3 ip address show--显示协议地址. 缩写:show、list、lst、sh、ls、l # ip addr ls eth0 5.4.ip address flush--清除协议地址. 缩写:flush、f 示例1 : 删除属于私网10.0.0.0/8的所有地址: # ip -s -s a f to 10/8 示例2 : 取消所有以太网卡的IP地址 # ip -4 addr flush label "eth0" 6. ip neighbour--neighbour/arp表管理命令 缩写 neighbour、neighbor、neigh、n 命令 add、change、replace、delete、fulsh、show(或者list) 6.1 ip neighbour add -- 添加一个新的邻接条目 ip neighbour change--修改一个现有的条目 ip neighbour replace--替换一个已有的条目 缩写:add、a;change、chg;replace、repl 示例1: 在设备eth0上,为地址10.0.0.3添加一个permanent ARP条目: # ip neigh add 10.0.0.3 lladdr 0:0:0:0:0:1 dev eth0 nud perm 示例2:把状态改为reachable # ip neigh chg 10.0.0.3 dev eth0 nud reachable 6.2.ip neighbour delete--删除一个邻接条目 示例1:删除设备eth0上的一个ARP条目10.0.0.3 # ip neigh del 10.0.0.3 dev eth0 6.3.ip neighbour show--显示网络邻居的信息. 缩写:show、list、sh、ls 示例1: # ip -s n ls 193.233.7.254 193.233.7.254. dev eth0 lladdr 00:00:0c:76:3f:85 ref 5 used 12/13/20 nud reachable 6.4.ip neighbour flush--清除邻接条目. 缩写:flush、f 示例1: (-s 可以显示详细信息) # ip -s -s n f 193.233.7.254 7. 路由表管理 7.1.缩写 route、ro、r 7.2.路由表 从Linux-2.2开始,内核把路由归纳到许多路由表中,这些表都进行了编号,编号数字的范围是1到255。另外, 为了方便,还可以在/etc/iproute2/rt_tables中为路由表命名。 默认情况下,所有的路由都会被插入到表main(编号254)中。在进行路由查询时,内核只使用路由表main。 7.3.ip route add -- 添加新路由 ip route change -- 修改路由 ip route replace -- 替换已有的路由 缩写:add、a;change、chg;replace、repl 示例1: 设置到网络10.0.0/24的路由经过网关193.233.7.65 # ip route add 10.0.0/24 via 193.233.7.65 示例2: 修改到网络10.0.0/24的直接路由,使其经过设备dummy # ip route chg 10.0.0/24 dev dummy 示例3: 实现链路负载平衡.加入缺省多路径路由,让ppp0和ppp1分担负载(注意:scope值并非必需,它只不过是告诉内核, 这个路由要经过网关而不是直连的。实际上,如果你知道远程端点的地址,使用via参数来设置就更好了)。 # ip route add default scope global nexthop dev ppp0 nexthop dev ppp1 # ip route replace default scope global nexthop dev ppp0 nexthop dev ppp1 示例4: 设置NAT路由。在转发来自192.203.80.144的数据包之前,先进行网络地址转换,把这个地址转换为193.233.7.83 # ip route add nat 192.203.80.142 via 193.233.7.83 示例5: 实现数据包级负载平衡,允许把数据包随机从多个路由发出。weight 可以设置权重. # ip route replace default equalize nexthop via 211.139.218.145 dev eth0 weight 1 nexthop via 211.139.218.145 dev eth1 weight 1 7.4.ip route delete-- 删除路由 缩写:delete、del、d 示例1:删除上一节命令加入的多路径路由 # ip route del default scope global nexthop dev ppp0 nexthop dev ppp1 7.5.ip route show -- 列出路由 缩写:show、list、sh、ls、l 示例1: 计算使用gated/bgp协议的路由个数 # ip route ls proto gated/bgp |wc 1413 9891 79010 示例2: 计算路由缓存里面的条数,由于被缓存路由的属性可能大于一行,以此需要使用-o选项 # ip -o route ls cloned |wc 159 2543 18707 示例3: 列出路由表TABLEID里面的路由。缺省设置是table main。TABLEID或者是一个真正的路由表ID或者是/etc/iproute2/rt_tables文件定义的字符串, 或者是以下的特殊值: all -- 列出所有表的路由; cache -- 列出路由缓存的内容。 ip ro ls 193.233.7.82 tab cache 示例4: 列出某个路由表的内容 # ip route ls table fddi153 示例5: 列出默认路由表的内容 # ip route ls 这个命令等于传统的: route 7.6.ip route flush -- 擦除路由表 示例1: 删除路由表main中的所有网关路由(示例:在路由监控程序挂掉之后): # ip -4 ro flush scope global type unicast 示例2:清除所有被克隆出来的IPv6路由: # ip -6 -s -s ro flush cache 示例3: 在gated程序挂掉之后,清除所有的BGP路由: # ip -s ro f proto gated/bgp 示例4: 清除所有ipv4路由cache # ip route flush cache *** IPv4 routing cache is flushed. 7.7 ip route get -- 获得单个路由 .缩写:get、g 使用这个命令可以获得到达目的地址的一个路由以及它的确切内容。 ip route get命令和ip route show命令执行的操作是不同的。ip route show命令只是显示现有的路由,而ip route get命令在必要时会派生出新的路由。 示例1: 搜索到193.233.7.82的路由 # ip route get 193.233.7.82 193.233.7.82 dev eth0 src 193.233.7.65 realms inr.ac cache mtu 1500 rtt 300 示例2: 搜索目的地址是193.233.7.82,来自193.233.7.82,从eth0设备到达的路由(这条命令会产生一条非常有意思的路由,这是一条到193.233.7.82的回环路由) # ip r g 193.233.7.82 from 193.233.7.82 iif eth0 193.233.7.82 from 193.233.7.82 dev eth0 src 193.233.7.65 realms inr.ac/inr.ac cache mtu 1500 rtt 300 iif eth0 8. ip route -- 路由策略数据库管理命令 命令 add、delete、show(或者list) 注意:策略路由(policy routing)不等于路由策略(rouing policy)。 在某些情况下,我们不只是需要通过数据包的目的地址决定路由,可能还需要通过其他一些域:源地址、IP协议、传输层端口甚至数据包的负载。 这就叫做:策略路由(policy routing)。 8.1. ip rule add -- 插入新的规则 ip rule delete -- 删除规则 缩写:add、a;delete、del、d 示例1: 通过路由表inr.ruhep路由来自源地址为192.203.80/24的数据包 ip ru add from 192.203.80/24 table inr.ruhep prio 220 示例2:把源地址为193.233.7.83的数据报的源地址转换为192.203.80.144,并通过表1进行路由 ip ru add from 193.233.7.83 nat 192.203.80.144 table 1 prio 320 示例3:删除无用的缺省规则 ip ru del prio 32767 8.2. ip rule show -- 列出路由规则 缩写:show、list、sh、ls、l 示例1: # ip ru ls 0: from all lookup local 32762: from 192.168.4.89 lookup fddi153 32764: from 192.168.4.88 lookup fddi153 32766: from all lookup main 32767: from all lookup 253 9. ip maddress -- 多播地址管理 缩写:show、list、sh、ls、l 9.1.ip maddress show -- 列出多播地址 示例1: # ip maddr ls dummy 9.2. ip maddress add -- 加入多播地址 ip maddress delete -- 删除多播地址 缩写:add、a;delete、del、d 使用这两个命令,我们可以添加/删除在网络接口上监听的链路层多播地址。这个命令只能管理链路层地址。 示例1: 增加 # ip maddr add 33:33:00:00:00:01 dev dummy 示例2: 查看 # ip -O maddr ls dummy 2: dummy link 33:33:00:00:00:01 users 2 static link 01:00:5e:00:00:01 示例3: 删除 # ip maddr del 33:33:00:00:00:01 dev dummy 10.ip mroute -- 多播路由缓存管理 10.1. ip mroute show -- 列出多播路由缓存条目 缩写:show、list、sh、ls、l 示例1:查看 # ip mroute ls (193.232.127.6, 224.0.1.39) Iif: unresolved (193.232.244.34, 224.0.1.40) Iif: unresolved (193.233.7.65, 224.66.66.66) Iif: eth0 Oifs: pimreg 示例2:查看 # ip -s mr ls 224.66/16 (193.233.7.65, 224.66.66.66) Iif: eth0 Oifs: pimreg 9383 packets, 300256 bytes 11. ip tunnel -- 通道配置 缩写 tunnel、tunl 11.1.ip tunnel add -- 添加新的通道 ip tunnel change -- 修改现有的通道 ip tunnel delete -- 删除一个通道 缩写:add、a;change、chg;delete、del、d 示例1:建立一个点对点通道,最大TTL是32 # ip tunnel add Cisco mode sit remote 192.31.7.104 local 192.203.80.1 ttl 32 11.2.ip tunnel show -- 列出现有的通道 缩写:show、list、sh、ls、l 示例1: # ip -s tunl ls Cisco 12. ip monitor和rtmon -- 状态监视 ip命令可以用于连续地监视设备、地址和路由的状态。这个命令选项的格式有点不同,命令选项的名字叫做monitor,接着是操作对象: ip monitor [ file FILE ] [ all | OBJECT-LIST ] 示例1: # rtmon file /var/log/rtmon.log 示例2: # ip monitor file /var/log/rtmon.log r
转自:http://www.unixnotes.net/ip-rule.html?replytocom=25
相关资料:
- linux|tasklet机制
- linux|Struts学习笔记:Struts Framework工作原理
- linux|iReport-4.7.0转pdf中文字符集问题
- linux|ip rule 命令
- linux|shell编程下的AWK语法小结
- linux|ioremap函数解析
- linux|ioremap原理及意义
http://www.cppblog.com/isware/archive/2011/06/01/147825.html
Linux的高级路由和流量控制:介绍iproute2
发布时间:2014-12-19 更新时间:2014-12-26 来源:网络
作者:水笔思思关键词: Linux 流量控制 iproute2 高级路由
希望这篇文档能对你更好地理解Linxs2.2/2.4的路由有所帮助和启发。不被大多数使用者所知道的是,你所使用工具,其实能够完成相当规模工作。比如route 和ifconfig,实际上暗中调用了非常强大的iproute 2的底层基本功能。
Linux能为你做什么
一个小列表:
• 管制某台计算机的带宽
• 管制通向某台计算机的带宽• 帮助你公平地共享带宽• 保护你的网络不受DoS攻击• 保护Internet不受到你的客户的攻击• 把多台服务器虚拟成一台,进行http://www.aliyun.com/zixun/aggregation/13996.html">负载均衡或者提高可用性• 限制对你的计算机的访问• 限制你的用户访问某些主机• 基于用户账号(没错!)、MAC地址、源IP地址、端口、服务类型、时间或者内容等条件进行路由。现在,很多人都没有用到这些高级功能。这有很多原因。比如提供的文档过于冗长而且不容易上手,而且流量控制甚至根本就没有归档。
1 为什么使用 iproute2?
现在,绝大多数 Linux 发行版和绝大多数 UNIX都使用古老的arp, ifconfig和route命令。虽然这些工具能够工作,但它们在Linux2.2和更高版本的内核上显得有一些落伍。比如,现在GRE隧道已经成为了路由的一个主要概念,但却不能通过上述工具来配置。
使用了iproute2,隧道的配置与其他部分完全集成了。2.2 和更高版本的Linux 内核包含了一个经过彻底重新设计的网络子系统。这些新的代码让Linux在操作系统的竞争中取得了功能和性能上的优势。实际上,Linux新的路由、过滤和分类代码,从功能和性能上都不弱于现有的那些专业的路由器、防火墙和流量整形产品。
随着新的网络概念的提出,人们在现有操作系统的现有体系上修修补补来实现他们。这种固执的行为导致了网络代码中充斥着怪异的行为,这有点像人类的语言。过去,Linux模仿了SunOS的许多处理方式,并不理想。
这个新的体系则有可能比以往任何一个版本的Linux都更善于清晰地进行功能表达。
2 iproute2 概览
Linux有一个成熟的带宽供给系统,称为Traffic Control(流量控制)。这个系统支持各种方式进行分类、排序、共享和限制出入流量。
我们将从 iproute2 各种可能性的一个简要概览开始。
3 先决条件
你应该确认已经安装了用户级配置工具。这个包的名字在RedHat和Debian中都叫作“iproute”,也可以在这个地方找到:
ftp://ftp.inr.ac.ru/ip-routing/iproute2-2.2.4-now-ss??????.tar.gz
你也可以试试在这里(ftp://ftp.inr.ac.ru/ip-routing/iproute2-current.tar.gz)找找最新版本。
iproute 的某些部分需要你打开一些特定的内核选项。应该指出的是,RedHat6.2及其以前的所有发行版中所带的缺省内核都不带有流量控制所需要的绝大多数功能。
而RedHat 7.2在缺省情况下能满足所有要求。
另外,确认一下你的内核支持netlink ,Iproute2需要它.
本站所有文章全部来源于互联网,版权归属于原作者。本站所有转载文章言论不代表本站观点,如是侵犯了原作者的权利请发邮件联系站长(yanjing@alibaba-inc.com),我们收到后立即删除。
http://man.chinaunix.net/linux/lfs/LFS-6.1.1/chapter06/iproute2.html
6.32. IPRoute2-2.6.11-050330
IPRoute2 包含了基本的和高级的基于 IPv4 网络的程序。
6.32.1. 安装 IPRoute2
这个程序包中的二进制文件 arpd 依赖于 Berkeley DB 。因为 arpd 对于一个基本 Linux 系统基本上没有用处,所以我们要使用下面的补丁去除对 Berkeley DB 的依赖。如果你需要使用 arpd 你可以参考 BLFS-Book 中的这个页面来了解如何编译与安装 Berkeley DB :http://www.linuxfromscratch.org/blfs/view/svn/server/databases.html#db 。
sed -i '/^TARGETS/s@arpd@@g' misc/Makefile
为编译 IPRoute2 做准备:
./configure
编译软件包:
make SBINDIR=/sbin
make 选项的含义:
- SBINDIR=/sbin
-
确保将 IPRoute2 包中的二进制文件安装到 /sbin 目录中以符合 FHS 标准,因为一些 IPRoute2 二进制文件将会被 LFS-Bootscripts 使用。
安装软件包:
make SBINDIR=/sbin install
6.32.2. IPRoute2 的内容
简要描述
| ctstat | 连接状态工具 |
| ifcfg | ip 命令的shell脚本包装 |
| ifstat | 显示网络接口的统计信息,包括接口发送和接收到的包数量。 |
| ip | 主可执行程序,它包含以下几个功能: ip link [device] 查看和修改设备状态 ip addr 查看地址的特性,添加新地址、删除旧地址。 ip neighbor 查看邻居的特性,添加新邻居、删除旧邻居。 ip rule 查看和修改路由规则 ip route 查看路由表和修改路由表规则 ip tunnel 查看和修改 IP 隧道及其特性 ip maddr 查看和修改多播地址及其特性 ip mroute 设置、修改、删除多播路由 ip monitor 不间断的监视设备状态、地址、路由 |
| lnstat | 提供 Linux 网络统计信息,用于替代旧的 rtstat 程序。 |
| nstat | 显示网络统计信息 |
| routef | ip route 的一个组件,用于刷新路由表。 |
| routel | ip route 的一个组件,用于列出路由表。 |
| rtacct | 显示 /proc/net/rt_acct 文件的内容 |
| rtmon | 路由监视工具 |
| rtpr | 将 ip -o 的输出转换为可读的格式 |
| rtstat | 路由状态工具 |
| ss | 类似于 netstat 命令,显示活动的连接。 |
| tc | 流量控制,用于实现服务质量(QOS)和服务级别(COS): tc qdisc 建立排队规则 tc class 建立基于级别的队列调度 tc estimator 估算网络流量 tc filter 设置 QOS/COS 包过滤器 tc policy 设置 QOS/COS 规则
|
http://blog.csdn.net/dog250/article/details/6685633
Linux路由应用-使用策略路由实现访问控制
目录(?)[+]
引:
一般而言,访问控制并不是路由模块完成的,而是防火墙的职责,如果你使用Linux的,这是iptables的职责。然而有时候,特别是在策略很多的情况下,使用iptables会极大降低网络性能,这是Netfilter的filter表的本质决定的,具体的优化参见《Linux的Netfilter框架深度思考-对比Cisco的ACL》。 Linux有一个很实用的特性可以在某些情形下代替iptables,从而实现访问控制。本文给出一个方法,说明如何使用策略路由来控制数据访问的入口网卡,具体来讲就是:只有通过特定的网卡才能访问机器上的某一个地址。具体来讲,Linux服务器有如下配置: eth0:192.168.1.1/24 eth1:192.168.2.1/24 eth2:172.16.1.1/24 lo:127.0.0.1 只能通过eth0访问192.168.1.1这个地址,而不能通过eth1或者eth2访问,甚至本机都不能访问192.168.1.1。 但是在探讨如何做之前,首先要明白一些理论知识,这样才能知其然且知其所以然。1.完成这个需求必须要明白的背景知识
1.1.Linux路由查找流程
所有的路由器设计都要遵循以下规则: IF 目的地址配置在本机 THEN 本机接收ELSE 查找路由表并在找到路由的情况下转发END 当然Linux也不能例外,但是Linux并没有将这这两种情况进行区分,而是使用“多张路由表”将二者统一了起来。在Linux中,内置了三张路由表: local,main,default,其中local路由表的优先级最高,并且不能被替换,在有数据包进来的时候,首先无条件的查找local路由表,如果找到了路由,则数据包就是发往本机的,如果找不到,则接着在其它的路由表中进行查找。使用ip route ls table local命令可以看到local表的内容,比如机器的eth0网卡上配有192.168.0.7,则在local表中会有如下的路由: local 192.168.0.7 dev eth0 proto kernel scope host src 192.168.0.7 值得注意的是,local表中的路由是可以删除的。路由的src项指的是当数据包从本机发出时,在local表中找到了源地址的路由,首选的源ip地址 在local表和main表之间,可以插入251张策略路由表,因此如果有策略路由表的话,如果local表中没有找到路由,则会查找策略路由表。 总结一下本节的内容,Linux内置了三张路由表,其中local路由表优先级最高且不可替换,它完成“IF 目的地址配置在本机 THEN 本机接收”这个逻辑,在local表之后,可以配置多张策略路由表,策略路由的知识本文不谈,但是基本就是根据源地址,目的地址,出接口,入接口等元素来决定数据包在路由前是否进入该张策略路由表,本质上是一种过滤行为(然则结果是可以缓存的,其要点就在于此!)。1.2.bind地址/no-bind地址
有一个问题,那就是如果一个数据包从本机发出,如何确定其源地址,这个问题如果搞不明白,就可能面临很多奇怪的现象而无法解释,在这个问题上,TCP和UDP的行为是不同的,TCP比较简单,因为一个TCP连接是四元素决定的(源IP地址,目的IP地址,源端口,目的端口),因此在建立连接后,源/目的IP地址是确定的。对于UDP而言,情况就复杂了,下节详述。但是不管什么协议,在API接口层次上,一个socket分为bind地址的和不bind地址的。 如果是bind地址,那么源地址就是bind的那个地址,如果没有bind,那么源地址在路由之后根据路由的结果确定。这就意味着,策略路由的from关键字将无法匹配到所有没有bind地址的应用程序从本地发出的包-原因是策略路由匹配是在路由前做的,而此时还没有源IP地址。 想明白协议栈如何这么设计,还是要从IP路由的本质以及传输层语义来分析。IP路由的职责就是能将IP数据报送到目的地,在路由之后选择源IP地址可以使返回的IP数据报在完全逆向路径上返回。考虑传输层的语义,对于TCP而言,其源地址的确定性是TCP做的,而不是IP层做的,这一点一定要清楚。对于不bind地址的情况,应用程序在数据包到达网络层之前不需要考虑网络层协议头的内容,这个工作完全有网络层的IP路由模块来完成,应用程序只需要指出目的IP即可,完全由协议栈负责网络层协议头的添加。 想明白协议栈如何实现这个逻辑,最好的办法是看Linux的源代码,方法是跟踪一个数据包发送的全过程源码,具体看ip_route_output_slow。1.3.UDP踢皮球
讨论TCP的文章很多,TCP也有很多复杂的特性值得去深究,然而UDP也不是吃素的,有一种现象就是UDP连接会踢皮球,最终用TCPDUMP抓取的数据包结果会让人焦头烂额。其实只要明白1.2节的内容,本节的内容就很简单了。 UDP无连接,不可靠,只负责将数据尽力而为传到目的主机,它对源和目的IP地址的管理很松散,UDP数据流(更确切的并不能称为数据流)是单包的。在两端都没有显式bind到具体的IP地址的情况下,最终的数据包可以使用任意的本机地址,关键看路由的结果。数据到达对端之后,如果对端也没有显示bind到具体的IP地址,那么回复包的源地址也可能不再是初始包的目的地址。我们还是用实例来说明吧,先看网络拓扑: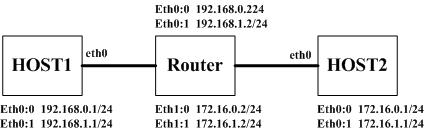 路由配置如下: host1:default 192.168.0.2host2:default 172.16.0.2 host1上运行一个UDP服务器,绑到0.0.0.0这个地址,也就是不绑定地址,host2向host1 192.168.1.1的UDP端口8888发送数据,抓包发现其源地址是172.16.0.1,目的地址是192.168.1.1,而返回包却抓不到了,意外抓取到一个源地址是192.168.0.1,目的地址是172.16.0.1的数据包。这是正常的,因为数据包到达host1时,查找返回路由时,会查到下一跳192.168.0.2,进而根据这个下一跳选择同一网段的192.168.0.1这个地址,此时如果添加一条路由:172.16.0.1 gw 192.168.1.2,那么就会看到返回数据包源地址为192.168.1.1了。 还有更奇怪的现象,那就是,初始时从host2向host1发送数据,源和目的分别是172.16.0.1和192.168.1.1,可是后来,在没有断开UDP客户端和服务器的情况下(host2更改了路由),源和目的分别成了172.16.1.1和192.168.0.1,这也是正常的,因为UDP本来就是无连接的,在不bind地址的情况下,关键是根据路由来选择源地址,选择源地址原则是:优先选择路由结果接口上和下一跳地址为同一网段的第一个primary地址,否则选择其它网卡上的primary地址,在选择过程中,有三个scope会影响选择结果,一个是下一跳地址scope,它表示该地址到达本地的“距离”,另一个是路由scope,它表示到达该路由的“距离”,还有一个是本地地址的scope,它限制了该地址的使用范围,路由模块保证下一跳的scope要小于路由的scope-背后的思想就是下一跳一定距离目的地比本机更近,而选择的本地地址的scope必须小于等于给定的scope(作为一个参数存在)。 UDP踢皮球有一个后果就是会影响Netfilter的ip_conntrack,我们知道,ip_conntrack是基于五元素来跟踪连接的,UDP的混乱情况可能使一个UDP数据流被跟踪好几次,从而使得后续的NAT规则(如果有的话)很复杂,NAT配置必须考虑到皮球的每一个方向,否则就会漏掉本来应该被NAT的数据包。 总之,网络是很复杂的,千万不要觉得就是配置几个IP地址以及几条路由那么简单的事。
路由配置如下: host1:default 192.168.0.2host2:default 172.16.0.2 host1上运行一个UDP服务器,绑到0.0.0.0这个地址,也就是不绑定地址,host2向host1 192.168.1.1的UDP端口8888发送数据,抓包发现其源地址是172.16.0.1,目的地址是192.168.1.1,而返回包却抓不到了,意外抓取到一个源地址是192.168.0.1,目的地址是172.16.0.1的数据包。这是正常的,因为数据包到达host1时,查找返回路由时,会查到下一跳192.168.0.2,进而根据这个下一跳选择同一网段的192.168.0.1这个地址,此时如果添加一条路由:172.16.0.1 gw 192.168.1.2,那么就会看到返回数据包源地址为192.168.1.1了。 还有更奇怪的现象,那就是,初始时从host2向host1发送数据,源和目的分别是172.16.0.1和192.168.1.1,可是后来,在没有断开UDP客户端和服务器的情况下(host2更改了路由),源和目的分别成了172.16.1.1和192.168.0.1,这也是正常的,因为UDP本来就是无连接的,在不bind地址的情况下,关键是根据路由来选择源地址,选择源地址原则是:优先选择路由结果接口上和下一跳地址为同一网段的第一个primary地址,否则选择其它网卡上的primary地址,在选择过程中,有三个scope会影响选择结果,一个是下一跳地址scope,它表示该地址到达本地的“距离”,另一个是路由scope,它表示到达该路由的“距离”,还有一个是本地地址的scope,它限制了该地址的使用范围,路由模块保证下一跳的scope要小于路由的scope-背后的思想就是下一跳一定距离目的地比本机更近,而选择的本地地址的scope必须小于等于给定的scope(作为一个参数存在)。 UDP踢皮球有一个后果就是会影响Netfilter的ip_conntrack,我们知道,ip_conntrack是基于五元素来跟踪连接的,UDP的混乱情况可能使一个UDP数据流被跟踪好几次,从而使得后续的NAT规则(如果有的话)很复杂,NAT配置必须考虑到皮球的每一个方向,否则就会漏掉本来应该被NAT的数据包。 总之,网络是很复杂的,千万不要觉得就是配置几个IP地址以及几条路由那么简单的事。 1.4.路由前对本机出发数据包的源地址的检查
如果是本机发出数据包,最终要进入路由模块的ip_route_output_slow函数来查找路由,该函数对bind地址的源地址进行了检查,它保证到该本地地址的路由必须在local路由表中被找到。- static int ip_route_output_slow(...)
- {
- if (oldflp->fl4_src) {
- ...
- if (!(oldflp->flags & FLOWI_FLAG_ANYSRC)) {
- /* It is equivalent to inet_addr_type(saddr) == RTN_LOCAL */
- dev_out = ip_dev_find(net, oldflp->fl4_src);
- if (dev_out == NULL)
- goto out;
- ...
- }
- }
- }
- local_table = fib_get_table(net, RT_TABLE_LOCAL);
- if (!local_table || local_table->tb_lookup(local_table, &fl, &res))
- return NULL;
1.5.Linux的IP地址属于主机而不属于网卡
在Linux中,不要以为IP地址是属于网卡的,它是属于主机的,实际上就算是UNIX或者其它的OS,IP地址都不应该是网卡的,IP地址是三层概念,网卡是二层设备。很多人都认为IP地址是属于网卡的是因为在Linux中配置IP地址时都要给定一个网卡参数,比如ip address add dev ethX XXX/YY。 IP地址是属于主机的,这就意味着,只要IP数据报到达本机,没有常规的方式使用路由限制该IP数据报不到达本地应用程序(local表是无条件最先被查询的,除非在local表中将该地址对应的local路由删除)。在procfs中使用sysctl能通过配置网卡参数达到限制数据包的目的吗?比如什么“关闭eth0的forwarding,这样数据包就不能从eth0 forward到eth2了”,根本不是那回事。1.6.取消本地地址必须存在于local路由表的限制
2.6.27以上内核的socket选项IP_TRANSPARENT可以影响本机出发数据包路由查找时的源地址检测,具体做法是在应用程序中使用下列代码段: int value = 1; setsockopt(fd, SOL_IP, IP_TRANSPARENT, &value, sizeof(value)); 设置后,服务器回包的源地址不再限制在local表内,而是可以使用任何地址,包括非本机地址,这个技术一般用于透明代理。因此可以用这一特性来利用策略路由表完成本应该由防火墙完成的功能,不损耗性能。这样可以做到在local表中将eth0上的local路由删除,将该local路由加到策略路由中,本地应用程序将不能访问配置在eth0上地址。 在2.6.27之前,协议栈在添加源地址(或者用户指定了侦听地址)时,要确保local路由表中拥有该地址,否则会报错,而我们就是想把该地址的本机local路由移出local表,因此此功能不可实现。在2.6.27之后,增加了FLOWI_FLAG_ANYSRC标志,可以通过设置该标志做到限制的取消,具体做法有两种,一种是全局的,那就是将ip_route_output_slow中的if (!(oldflp->flags & FLOWI_FLAG_ANYSRC))判断取消掉,改为if (0);第二种改法是基于socket的,实际上FLOWI_FLAG_ANYSRC是基于单个socket设置的。完成此功能的前提: 1).内核编译了CONFIG_IP_MULTIPLE_TABLES 2).修改管理服务程序,为其socket增加IP_TRANSPARENT选项2.具体操作
为了很简单的几步操作,前面啰里啰嗦说了那么多,实际上做技术本来就应该这样,必须挖掘深层次的原理,否则就只能算个IT工人。 配置: eth0:192.168.0.1/24eth1:172.16.0.1/24eth2:10.0.0.1/24lo:127.0.0.12.1.限制从其它网卡接口访问特定网卡接口上配置的IP地址(这个说法不准确,具体见1.5节)对应的服务
2.1.1.添加一个策略路由表
echo "100 my" >> /etc/iproute2/rt_tables 这样可以在local和main表之间增加一个路由表my,内核路由模块的查找顺序是:local->my->main...2.1.2.增加一条策略
ip rule add from 192.168.0.1 table my2.1.3.在策略路由表中增加所有从eth0出去的路由
ip route add 12.34.0.0/16 via 192.168.0.2 dev eth0 table myip route add ... table my...ip route add default dev eth0 table my 所有匹配到my这个策略路由表的数据包,将从上述的路由项中查询结果。注意,最后一条默认路由是必须要的,且一定要从eth0出去,否则根据Linux策略路由查找原则,如果在my表中没有找到路由的话,还是会继续往下进行的,所谓的策略路由表只是一个优先级问题,而不是强制的查找约束。2.1.4.结论和问题
通过以上的配置,所有从eth0进来的数据包才能安全返回,否则,比如从eth1进来一个访问192.168.0.1的数据包,由于它只有从eth1返回才可以(不考虑多径路由),然而返回包的源地址却是192.168.0.1(对应的服务不管是TCP的还是UDP必须显式bind到192.168.0.1这个地址,否则对于UDP就会有踢皮球的现象),这样路由查找就会进入my表(对于踢皮球的情况,就可能不进入my表),然则my表中没有一个从eth1出去的路由,且该包起码会匹配到my表的默认路由,数据包因此无法返回。 现在考虑一下一个问题,如果是bind到192.168.0.1这个地址的服务主动访问外部,是不是也一定要从eth0出去呢?答案是肯定的,因为它bind了一个明确的地址,而源地址是该地址的数据包一定会匹配到my,最终起码会匹配到my的默认路由...2.1.5.进一步的问题
现在已经实现了不能从除eth0之外的其它接口进入访问bind到eth0上地址的服务,然而如果希望做到连本地都不能访问该服务,那才是名副其实的“除eth0之外的...都不能...”,无疑本地出发的访问192.168.0.1的数据包肯定不是从eth0进入的。 有一个办法可以解决这个问题,那就是禁用掉lo,因为在Linux中,所有从本地到本地的包都会被定向掉lo,禁掉lo后,所有本地到本地的包就都无法到达目的地。但是这种方法并不好,管不着人家就把人家关起来,非真的猛士!下一节我们就看看怎么做到本地不能访问本地eth0上的192.168.0.1这个地址,做到名副其实的“只有eth0进入的数据包才能访问”2.2.限制本地访问本地bind到eth0上192.168.0.1这个地址的服务
想理解这个配置原理,还要回顾一下1.4节和1.6节,当理解了这两节之后,这里的配置就手到擒来了2.2.0.前提:两种方式
之一:直接将内核中的检查取消掉,见1.6节 之二:改写bind到192.168.0.1地址服务程序,为其socket增加IP_TRANSPARENT选项,2.2.1.添加一个新路由表
echo “100 my_rule” >> /etc/iproute2/rt_tables2.2.2.增加一条策略:从eth0到来的数据包,开放my_rule路由表
ip rule add iif eth0 table my_rule 所有从eth0进来的数据包,查找my_rule表中的路由2.2.3.为新增策略增加190.7 local路由
ip route add local 192.168.0.1/32 dev lo table my_rule 由于到达本地的数据包要想成功到达,必须要找到一条local路由(类型对即可,无需非要在local表),因此在my_rule中增加一条到达192.168.0.1的local路由2.2.4.删除原有的local表中的192.168.0.1路由
ip route del local 192.168.0.1/32 table local 由于2.2.0中的两种前提,对源地址的检测已经取消了,到达源地址的路由现在没有必要非要在local表中了,因此即使删除了local中到达192.168.0.1的路由,也无所谓,返回包会直接使用源地址192.168.0.1而不被检查。2.2.5.结论和问题
2.2.1-2.2.4的结果就是:访问192.168.0.1的数据包从eth0而来,查找my_rule表,找到,对于返回包,由于IP_TRANSPARENT取消了限制,可以正常返回;对于从非eth0到来的访问192.168.0.1的包,由于192.168.0.1的local路由已然被删,my_rule由于只匹配入口为eth0的数据包因而不对其开放,将无法访问。 这个配置在2.1节的基础上做了增强,然而由于要修改bind到192.168.0.1地址的服务程序,对于既有的闭源程序的类似的访问控制将没有用武之地(这些程序没有源码,不能修改)。3.总的结论
本文给出了一种使用路由进行访问控制的方式,对于规则比较简单,且访问控制都在第三层的场景中,路由的方式要比用防火墙更好,不会影响性能。然而本文的讨论完全是基于Linux的,对于非Linux的系统,比如Cisco,可能人家的ACL防火墙实现得比较高效,比iptables配置的更好,也就不需要用路由的方式进行访问控制了,就算对于Linux本身,nf-HiPAC对filter表做了优化之后,路由的方式进行访问控制的优势也减少了。总之,Linux网络或者说网络本身是一个超级复杂的系统,不同的实现对于配置方式的选型影响巨大,然而有一个问题,比如像Windows这样的系统,你还不知道它的网络协议栈实现的内幕,那么它的配置肯定也就比较固定,那就是Microsoft的建议配置。
实际上,由于增加了策略路由表,查表的过程也是遍历,并且根据策略路由表的match一个一个比较,这个过程和filter表的查询过程几乎是一样的,则策略路由的优势体现在何方?实际上,路由和filter有一个区别,那就是路由是可以缓存的,而filter则是每包匹配的,有一种基于状态的防火墙可以“缓存”过滤结果,但是由于需要维护连接状态,这笔开销也是不可小觑的。路由缓存是完全独立的,路由完全缓存在一个hash表当中。 但是,如果路由缓存hash表的冲突链表过长(缓存太大了),或者hash算法太菜,在配置大量策略路由和配置iptables之间权衡的话,后者也不是总是处于劣势,孰是孰非,只有具体情况具体分析,只有分析了具体的性能数据才能有结论,否则只是纸上谈兵一纸空文。4.两篇文档
linux-source/Documentation/networking/tproxy.txt linux-source/Documentation/networking/policy-routing.txt懂得网络配置命令是一般技术人员必备的技术,经过一段时间的研究和学习,总结了一些常用的命令和示例以便日后查阅.
传统的在1--3点,ip高级路由命令在4--12点,两者部分可以通用,并达到同样的目的,但ip的功能更强大,可以实现更多的配置目的。首先,先了解传统的网络配置命令:1. 使用ifconfig命令配置并查看网络接口情况示例1: 配置eth0的IP,同时激活设备:# ifconfig eth0 192.168.4.1 netmask 255.255.255.0 up示例2: 配置eth0别名设备 eth0:1 的IP,并添加路由# ifconfig eth0:1 192.168.4.2# route add –host 192.168.4.2 dev eth0:1示例3:激活(禁用)设备# ifconfig eth0:1 up(down)示例4:查看所有(指定)网络接口配置# ifconfig (eth0)2. 使用route 命令配置路由表示例1:添加到主机路由# route add –host 192.168.4.2 dev eth0:1# route add –host 192.168.4.1 gw 192.168.4.250示例2:添加到网络的路由# route add –net IP netmask MASK eth0# route add –net IP netmask MASK gw IP# route add –net IP/24 eth1示例3:添加默认网关# route add default gw IP示例4:删除路由# route del –host 192.168.4.1 dev eth0:1示例5:查看路由信息# route 或 route -n (-n 表示不解析名字,列出速度会比route 快)3.ARP 管理命令示例1:查看ARP缓存# arp示例2: 添加# arp –s IP MAC示例3: 删除# arp –d IP4. ip是iproute2软件包里面的一个强大的网络配置工具,它能够替代一些传统的网络管理工具。例如:ifconfig、route等,上面的示例完全可以用下面的ip命令实现,而且ip命令可以实现更多的功能.下面介绍一些示例:4.0 ip命令的语法ip [OPTIONS] OBJECT [COMMAND [ARGUMENTS]]4.1 ip link set--改变设备的属性. 缩写:set、s示例1:up/down 起动/关闭设备。# ip link set dev eth0 up这个等于传统的 # ifconfig eth0 up(down)示例2:改变设备传输队列的长度。参数:txqueuelen NUMBER或者txqlen NUMBER# ip link set dev eth0 txqueuelen 100示例3:改变网络设备MTU(最大传输单元)的值。# ip link set dev eth0 mtu 1500示例4: 修改网络设备的MAC地址。参数: address LLADDRESS# ip link set dev eth0 address 00:01:4f:00:15:f14.2 ip link show--显示设备属性. 缩写:show、list、lst、sh、ls、l-s选项出现两次或者更多次,ip会输出更为详细的错误信息统计。示例:# ip -s -s link ls eth0 eth0: mtu 1500 qdisc cbq qlen 100 link/ether 00:a0:cc:66:18:78 brd ff:ff:ff:ff:ff:ff RX: bytes packets errors dropped overrun mcast 2449949362 2786187 0 0 0 0 RX errors: length crc frame fifo missed 0 0 0 0 0 TX: bytes packets errors dropped carrier collsns 178558497 1783946 332 0 332 35172 TX errors: aborted fifo window heartbeat 0 0 0 332 这个命令等于传统的 ifconfig eth0 5.1 ip address add--添加一个新的协议地址. 缩写:add、a示例1:为每个地址设置一个字符串作为标签。为了和Linux-2.0的网络别名兼容,这个字符串必须以设备名开头,接着一个冒号,# ip addr add local 192.168.4.1/28 brd + label eth0:1 dev eth0示例2: 在以太网接口eth0上增加一个地址192.168.20.0,掩码长度为24位(155.155.155.0),标准广播地址,标签为eth0:Alias:# ip addr add 192.168.4.2/24 brd + dev eth1 label eth1:1这个命令等于传统的: ifconfig eth1:1 192.168.4.25.2 ip address delete--删除一个协议地址. 缩写:delete、del、d# ip addr del 192.168.4.1/24 brd + dev eth0 label eth0:Alias15.3 ip address show--显示协议地址. 缩写:show、list、lst、sh、ls、l# ip addr ls eth05.4.ip address flush--清除协议地址. 缩写:flush、f示例1 : 删除属于私网10.0.0.0/8的所有地址:# ip -s -s a f to 10/8示例2 : 取消所有以太网卡的IP地址# ip -4 addr flush label "eth0"6. ip neighbour--neighbour/arp表管理命令缩写 neighbour、neighbor、neigh、n命令 add、change、replace、delete、fulsh、show(或者list)6.1 ip neighbour add -- 添加一个新的邻接条目ip neighbour change--修改一个现有的条目ip neighbour replace--替换一个已有的条目缩写:add、a;change、chg;replace、repl示例1: 在设备eth0上,为地址10.0.0.3添加一个permanent ARP条目:# ip neigh add 10.0.0.3 lladdr 0:0:0:0:0:1 dev eth0 nud perm示例2:把状态改为reachable# ip neigh chg 10.0.0.3 dev eth0 nud reachable6.2.ip neighbour delete--删除一个邻接条目示例1:删除设备eth0上的一个ARP条目10.0.0.3# ip neigh del 10.0.0.3 dev eth06.3.ip neighbour show--显示网络邻居的信息. 缩写:show、list、sh、ls示例1: # ip -s n ls 193.233.7.254193.233.7.254. dev eth0 lladdr 00:00:0c:76:3f:85 ref 5 used 12/13/20 nud reachable6.4.ip neighbour flush--清除邻接条目. 缩写:flush、f示例1: (-s 可以显示详细信息)# ip -s -s n f 193.233.7.2547. 路由表管理7.1.缩写 route、ro、r7.5.路由表从Linux-2.2开始,内核把路由归纳到许多路由表中,这些表都进行了编号,编号数字的范围是1到255。另外,为了方便,还可以在/etc/iproute2/rt_tables中为路由表命名。默认情况下,所有的路由都会被插入到表main(编号254)中。在进行路由查询时,内核只使用路由表main。7.6.ip route add -- 添加新路由ip route change -- 修改路由ip route replace -- 替换已有的路由缩写:add、a;change、chg;replace、repl示例1: 设置到网络10.0.0/24的路由经过网关193.233.7.65# ip route add 10.0.0/24 via 193.233.7.65示例2: 修改到网络10.0.0/24的直接路由,使其经过设备dummy# ip route chg 10.0.0/24 dev dummy示例3: 实现链路负载平衡.加入缺省多路径路由,让ppp0和ppp1分担负载(注意:scope值并非必需,它只不过是告诉内核,这个路由要经过网关而不是直连的。实际上,如果你知道远程端点的地址,使用via参数来设置就更好了)。# ip route add default scope global nexthop dev ppp0 nexthop dev ppp1# ip route replace default scope global nexthop dev ppp0 nexthop dev ppp1示例4: 设置NAT路由。在转发来自192.203.80.144的数据包之前,先进行网络地址转换,把这个地址转换为193.233.7.83# ip route add nat 192.203.80.142 via 193.233.7.83示例5: 实现数据包级负载平衡,允许把数据包随机从多个路由发出。weight 可以设置权重.# ip route replace default equalize nexthop via 211.139.218.145 dev eth0 weight 1 nexthop via 211.139.218.145 dev eth1 weight 17.7.ip route delete-- 删除路由缩写:delete、del、d示例1:删除上一节命令加入的多路径路由# ip route del default scope global nexthop dev ppp0 nexthop dev ppp17.8.ip route show -- 列出路由缩写:show、list、sh、ls、l示例1: 计算使用gated/bgp协议的路由个数# ip route ls proto gated/bgp |wc1413 9891 79010示例2: 计算路由缓存里面的条数,由于被缓存路由的属性可能大于一行,以此需要使用-o选项# ip -o route ls cloned |wc159 2543 18707示例3: 列出路由表TABLEID里面的路由。缺省设置是table main。TABLEID或者是一个真正的路由表ID或者是/etc/iproute2/rt_tables文件定义的字符串,或者是以下的特殊值:all -- 列出所有表的路由;cache -- 列出路由缓存的内容。ip ro ls 193.233.7.82 tab cache示例4: 列出某个路由表的内容# ip route ls table fddi153示例5: 列出默认路由表的内容# ip route ls这个命令等于传统的: route7.9.ip route flush -- 擦除路由表示例1: 删除路由表main中的所有网关路由(示例:在路由监控程序挂掉之后):# ip -4 ro flush scope global type unicast示例2:清除所有被克隆出来的IPv6路由:# ip -6 -s -s ro flush cache示例3: 在gated程序挂掉之后,清除所有的BGP路由:# ip -s ro f proto gated/bgp示例4: 清除所有ipv4路由cache# ip route flush cache*** IPv4 routing cache is flushed.7.10 ip route get -- 获得单个路由 .缩写:get、g使用这个命令可以获得到达目的地址的一个路由以及它的确切内容。ip route get命令和ip route show命令执行的操作是不同的。ip route show命令只是显示现有的路由,而ip route get命令在必要时会派生出新的路由。示例1: 搜索到193.233.7.82的路由# ip route get 193.233.7.82193.233.7.82 dev eth0 src 193.233.7.65 realms inr.ac cache mtu 1500 rtt 300示例2: 搜索目的地址是193.233.7.82,来自193.233.7.82,从eth0设备到达的路由(这条命令会产生一条非常有意思的路由,这是一条到193.233.7.82的回环路由)# ip r g 193.233.7.82 from 193.233.7.82 iif eth0193.233.7.82 from 193.233.7.82 dev eth0 src 193.233.7.65 realms inr.ac/inr.accache ; mtu 1500 rtt 300 iif eth08. ip route -- 路由策略数据库管理命令命令 add、delete、show(或者list)注意:策略路由(policy routing)不等于路由策略(rouing policy)。在某些情况下,我们不只是需要通过数据包的目的地址决定路由,可能还需要通过其他一些域:源地址、IP协议、传输层端口甚至数据包的负载。这就叫做:策略路由(policy routing)。8.5. ip rule add -- 插入新的规则ip rule delete -- 删除规则缩写:add、a;delete、del、d示例1: 通过路由表inr.ruhep路由来自源地址为192.203.80/24的数据包ip ru add from 192.203.80/24 table inr.ruhep prio 220示例2:把源地址为193.233.7.83的数据报的源地址转换为192.203.80.144,并通过表1进行路由ip ru add from 193.233.7.83 nat 192.203.80.144 table 1 prio 320示例3:删除无用的缺省规则ip ru del prio 327678.7. ip rule show -- 列出路由规则缩写:show、list、sh、ls、l示例1: # ip ru ls0: from all lookup local32762: from 192.168.4.89 lookup fddi15332764: from 192.168.4.88 lookup fddi15332766: from all lookup main32767: from all lookup 2539. ip maddress -- 多播地址管理缩写:show、list、sh、ls、l9.3.ip maddress show -- 列出多播地址示例1: # ip maddr ls dummy9.4. ip maddress add -- 加入多播地址ip maddress delete -- 删除多播地址缩写:add、a;delete、del、d使用这两个命令,我们可以添加/删除在网络接口上监听的链路层多播地址。这个命令只能管理链路层地址。示例1: 增加 # ip maddr add 33:33:00:00:00:01 dev dummy示例2: 查看 # ip -O maddr ls dummy2: dummylink 33:33:00:00:00:01 users 2 staticlink 01:00:5e:00:00:01示例3: 删除 # ip maddr del 33:33:00:00:00:01 dev dummy10.ip mroute -- 多播路由缓存管理10.4. ip mroute show -- 列出多播路由缓存条目缩写:show、list、sh、ls、l示例1:查看 # ip mroute ls(193.232.127.6, 224.0.1.39) Iif: unresolved(193.232.244.34, 224.0.1.40) Iif: unresolved(193.233.7.65, 224.66.66.66) Iif: eth0 Oifs: pimreg示例2:查看 # ip -s mr ls 224.66/16(193.233.7.65, 224.66.66.66) Iif: eth0 Oifs: pimreg9383 packets, 300256 bytes11. ip tunnel -- 通道配置缩写 tunnel、tunl11.4.ip tunnel add -- 添加新的通道ip tunnel change -- 修改现有的通道ip tunnel delete -- 删除一个通道缩写:add、a;change、chg;delete、del、d示例1:建立一个点对点通道,最大TTL是32# ip tunnel add Cisco mode sit remote 192.31.7.104 local 192.203.80.1 ttl 3211.4.ip tunnel show -- 列出现有的通道缩写:show、list、sh、ls、l示例1: # ip -s tunl ls Cisco12. ip monitor和rtmon -- 状态监视ip命令可以用于连续地监视设备、地址和路由的状态。这个命令选项的格式有点不同,命令选项的名字叫做monitor,接着是操作对象:ip monitor [ file FILE ] [ all | OBJECT-LIST ]示例1: # rtmon file /var/log/rtmon.log示例2: # ip monitor file /var/log/rtmon.log r
http://zhoulifa.bokee.com/6192551.html
高级网络工具iproute
IPRoute 的内容 安装的程序: ctstat (链接到 lnstat), ifcfg, ifstat, ip, lnstat, nstat, routef, routel, rtacct, rtmon, rtpr, rtstat (链接到 lnstat), ss, tc 简要描述
|
其中ss命令用法如下:
| Usage: ss [ OPTIONS ] ss [ OPTIONS ] [ FILTER ] -h, --help this message -V, --version output version information -n, --numeric don't resolve service names -r, --resolve resolve host names -a, --all display all sockets -l, --listening display listening sockets -o, --options show timer information -e, --extended show detailed socket information -m, --memory show socket memory usage -p, --processes show process using socket -i, --info show internal TCP information -s, --summary show socket usage summary -4, --ipv4 display only IP version 4 sockets -6, --ipv6 display only IP version 6 sockets -0, --packet display PACKET sockets -t, --tcp display only TCP sockets -u, --udp display only UDP sockets -d, --dccp display only DCCP sockets -w, --raw display only RAW sockets -x, --unix display only Unix domain sockets -f, --family=FAMILY display sockets of type FAMILY -A, --query=QUERY QUERY := {all|inet|tcp|udp|raw|unix|packet|netlink}[,QUERY] -F, --filter=FILE read filter information from FILE FILTER := [ state TCP-STATE ] [ EXPRESSION ] |
Linux高级路由---策略路由/捆绑/网桥
企图穿越 发布于 5年前,共有 0 条评论
1.策略路由
基于策略的路由比传统路由在功能上更强大,使用更灵活,它使网络管理员不仅能够根据目的地址而且能够根据报文大小、应用或IP源地址来选择转发路 径... #/etc/iproute2/rt_tables 此文件存有linux 系统路由表默认表有255 254 253三张表 255 local 本地路由表 存有本地接口地址,广播地址,已及NAT地址. local表由系统自动维护..管理员不能操作此表... 254 main 主路由表 传统路由表,ip route若没指定表亦操作表254.一般存所有的路由.. 注:平时用ip ro sh查看的亦是此表设置的路由. 253 default 默认路由表一般存放默认路由... 注:rt_tables文件中表以数字来区分表0保留最多支持255张表 路由表的查看可有以下二种方法: #ip route list table table_number传统路由器在网络和需求变得复杂时将无法满足需要,而一种基于策略的路由给了我们更好的选择。本文给出一个Linux下的配置实例,它在2.4G奔 腾4处理器、256M内存的计算机上运行通过,并在160多台电脑的网络环境下运转正常。
基于策略的路由比传统路由更强大,使用更灵活,它使网络管理者不仅能够根据目的地址而且能够根据报文大小、应用或IP源地址来选择转发路 径。在现实的网络应用中,这种选择的自由性还是很需要的。而Linux从2.1版本的内核开始就实现了对策略路由的支持,下面就介绍一个配置实例,以期对 读者有所帮助。
实例背景
如图所示,两个内部网通过远端路由器1与因特网相联,通过远端路由器2与上级网相联, Linux服务器做策略路由器,内有4块网卡。IP地址的分配情况如表所示。
在应用需求方面,内网1允许通过远端路由器1(172.22.254.254)连接因特网,但只允许Http协议、FTP协议经常性通过, 其他协议分时间段开放(这样做是为了避免员工在上班时间打网络游戏和聊天),例如在上班时间(7:30~16:30)封闭,在下班时间 (16:30~7:30)和周六、日全天开放。而且,内网1无权访问内网2及上级网,但可以访问内网2上的服务器。而允许内网2访问外网,上级网则只能访 问内网2上的192.168.1.2服务器。而防火墙主要用来阻止外网主动访问内网,防止网络攻击。
实现过程
这里我们选择Red Hat Enterprise Linux WS 3操作系统,其内核版本是2.4.21,对策略路由已经有了很好的支持,下面的配置也以此为基础。
1.设置IP地址
首先,执行如下命令:
ifconfig eth0 10.89.9.1 netmask 255.255.255.0
ifconfig eth1 192.168.1.1 netmask 255.255.255.0
ifconfig eth2 172.22.254.14 netmask 255.255.255.0
ifconfig eth3 10.140.133.14 netmask 255.255.255.0
为了让计算机启动时自动设置IP地址,还需要分别修改/etc/sysconfig/network-scripts/下的四个文 件:ifcfg-eth0、ifcfg-eth1、ifcfg-eth2、ifcfg-eth3,将ONBOOT属性设为yes,即 “ONBOOT=yes”,文件格式如下:
# Intel Corp.82545EM Gigabit Ethernet Controller (Copper)
DEVICE=eth0
BOOTPROTO=none
HWADDR=00:0c:76:20:54:71
ONBOOT=yes
TYPE=Ethernet
USERCTL=yes
PEERDNS=no
NETMASK=255.255.255.0
IPADDR=10.89.9.1
如果你不喜欢命令行模式,也可以在图形模式下进行以上操作:主菜单→系统设置→网络,设好IP地址并激活,并且选中“当计算机启动时激活设 备”选项。
2.打开转发功能
执行命令“echo “1” > /proc/sys/net/ipv4/ip_forward”,或者在/etc/sysconfig/network文件中添加 “FORWARD_IPV4=yes”。
3.创建路由表
编辑 /etc/iproute2/rt_tables 文件,执行如下命令。在这里新添加了4个路由表,分别为int1 、int2、int3、int4。
# reserved values
#255 local
#254 main
#253 default
#0 unspec
# local
#1 inr.ruhep
1 int1
2 int2
3 int3
4 int4
4.添加路由
执行如下命令:
ip route add default via 10.89.9.1 table int1
ip route add default via 192.168.1.1 table int2
ip route add default via 172.22.254.254 table int3
ip route add 192.168.0.0/16 via 10.140.133.254 table int4
ip route add default via 172.22.254.254 table int4
这里在int4路由表中添加了两条路由,当进入到该路由表之后,要到192.168.0.0/16的数据包则路由到 10.140.133.254,其他数据包则路由到172.22.254.254。
5.标记(MARK)特殊包
执行如下两条命令:
iptables -t mangle -A PREROUTING -p tcp -m multiport --dports 80,8080,20,21 -s 10.89.9.0/24 -j MARK --set-mark 1
iptables -t mangle -A PREROUTING -p udp --dport 53 -s 10.89.9.0/24 -j MARK --set-mark 2
这两条命令是将来自10.89.9.0/24的目的端口是80、8080、20或21的数据包和UDP端口是53的数据包分别标记为1或 2,然后就可以针对这些标记过的数据包制定相应的规则了。(对外发出的DNS请求用的是UDP 53端口)
为了实现防火墙的功能,只允许已经建立联机的数据包进入内网,就要把进入两个内网的已经建立联机的数据包进行标记。执行如下命令:
iptables -t mangle -A PREROUTING -p ALL -d 10.89.9.0/24 -m state --state ESTABLISHED,RELATED -j MARK --set-mark 3
iptables -t mangle -A PREROUTING -p ALL -d 192.168.1.0/24 -m state --state ESTABLISHED,RELATED -j MARK --set-mark 4
6.创建路由规则
执行如下命令:
ip rule add from 192.168.1.0/24 pref 11 table int4
ip rule add to 192.168.1.2 pref 21 table int2
ip rule add fwmark 4 pref 31 table int2
ip rule add fwmark 1 pref 41 table int3
ip rule add fwmark 2 pref 42 table int3
ip rule add fwmark 3 pref 51 table int1
接着执行命令“ip route flush cache”,刷新路由缓冲,让以上的这些命令立刻生效,否则需要等上一段时间。
7.实现分时间段控制
若是按照以上的配置,内网1的用户只能上网浏览网页和下载,为了对其他功能实现分时间段开放,需要做以下工作:
首先编辑命令脚本文件ropen (开放)和rclose (限制)。执行命令“vi /bin/ropen”,ropen文件内容如下:
/sbin/ip rule add from 10.89.9.0/24 pref 40 table int3
/sbin/ip route flush cache
执行命令“vi /bin/rclose”,rclose文件内容如下:
/sbin/ip rule del from 10.89.9.0/24 pref 40
/sbin/ip route flush cache
如果不习惯命令行方式,也可以在图形界面下生成这两个文件,生成文件之后,需要增加可执行属性方可执行:分别执行命令“chmod +x ropen”和“chmod +x rclose”。
接着,利用crontab命令实现自动运行。这里需要编辑一个文本文件,格式如下:
minute hour dayofmonth monthofyear dayofweek “命令”
其中每部分名称及取值范围是:minute代表分钟,取值范围是00~59;hour代表小时,取值范围是 00~23;dayofmonth代表某天,取值范围是01~31;monthofyear代表月份,取值范围是01~12;dayofweek代表星 期,取值范围是01~07。若需要忽略其中某一部分就用星号(*)代替。例如,文件名设为mycron,内容可编辑如下:
30 07 * * 01,02,03,04,05 "/bin/ropen"
30 16 * * 01,02,03,04,05 "/bin/rclose"
最后执行crontab命令,将所编辑的文件mycron装载并启动,命令为“crontab mycron”。
本文出自 “RHCSS系统安全架构师” 博客,转载请与作者联系!
-- 前提知识: --
如果需要使用策略路由需确认编译内核时配置中带有IP:advanced route和IP:policy routingiproute匹配条件:from源地址,to目的地址,Tos域,Dev物理接口,Fwmark防火墙标记 这些做为匹配条件iproute动作:可以以table指明所用的表,nat网络地址转换,prohibit丢弃并发送icmp信息,reject单纯丢弃,unreachable丢弃并发送icmp信息.ip rule首先程序从优先级高到低扫描所有的规则,如果规则匹配,处理该规则的动作。如果是普通的路由寻址或者是nat地址转换的换,首先从规则得到路由表,然后对该路由表进行操作。这样RPDB(routing policy database)终于清晰的显现出来了。 iproute相关的内核编译选项:CONFIG_IP_ADVANCED_ROUTER=y CONFIG_IP_MULTIPLE_TABLES=y CONFIG_IP_ROUTE_FWMARK=y/etc/iproute2/rt_tables 保存规则的名字与数字的关联iptables -A FORWARD -p tcp -m tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu 允许调整tcp syn包里的MSS域,用于控制连接包的最大长度。一些防火墙或主机会很不适当的过滤掉type 3、code 4(需要分片)的icmp包。目前发行的linux的内核从2.4.7开始已经包含了这个补丁。IMQ 中介队列设备被打了特定标记的数据包在netfilter的NF_IP_PRE_ROUTING和NF_IP_POST_ROUTING两个钩子函数处被拦截,并被送到一个队列规定中,该队列规定附加到一个IMQ设备上。可以实现对入口流量整形,而且可以把网卡当成一个个的类来看待而进行全局整形设置。--应用案例1 --通过iptables与iproute2协同实现根据 应用 的策略路由实现要点: iptables根据端口将服务类的数据包打上标示,iptables -t mangle -A PREROUTING -p tcp --dport 80 -j MARK --set-mark 100 (用这些标记我们可以做带宽限制和基于请求的分类)根据情况做nat iptables -t nat -A POSTROUTING -o eth2 -j MASQUERADE 然后设置路由策略ip rule add fwmark 100 table 100 -- 应用案例2 --普通双ISP的设置 外网接口$IF1 IF1接口地址$IP1 ISP1网关地址$P1 ISP1的网络地址P1_NET#分别指定两条默认网关负责单独的上行流ip route add $P1_NET dev $IF1 src $IP1 table T1 源地址为IP1且目的为ISP1网段从IF1接口发出(必需的,它能够让我们找到该子网内的主机及本网关) 将这条路由加入表T1ip route add default via $P1 table T1ip route add $P2_NET dev $IF2 src $IP2 table T2 源地址为IP2且目的为ISP2网段从IF2接口发出((必需的,它能够让我们找到该子网内的主机及本网关) 将这条路由加入表T2ip route add default via $P2 table T2#也加入到main路由表ip route add $P1_NET dev $IF1 src $IP1ip route add $P2_NET dev $IF2 src $IP2 main缺省走ISP1ip route add default via $P1#设置路由规则ip rule add from $IP1 table T1ip rule add from $IP2 table T2#设置负载均衡ip route add default scope global nexthop via $P1 dev $IF1 weight 1 \nexthop via $P2 dev $IF2 weight 1均衡是基于路由进行的,而路由是经过缓冲的,所以这样的均衡并不是100%精确.-- 应用案例3 -- TC带宽管理的主要实现步骤 主要是在输出端口处建立一个队列进行流量控制,控制的方式是基于路由,亦即基于目的IP地址或目的子网的网络号的流量控制。1 编译内核时注意事项以下实例:发往A主机8M带宽 发往B主机1M带宽 发往C主机1M带宽2 1) 针对网络物理设备(如以太网卡eth0)绑定一个CBQ队列; tc qdisc add dev eth0 root handle 1: cbq bandwidth 10Mbit avpkt 1000 cell 8 mpu 64 2) 在该队列上建立分类; tc class add dev eth0 parent 1:0 classid 1:1 cbq bandwidth 10Mbit rate 10Mbit maxburst 20 allot \ 1514 prio 8 avpkt 1000 cell 8 weight 1Mbit tc class add dev eth0 parent 1:1 classid 1:2 cbq bandwidth 10Mbit rate 8Mbit maxburst 20 allot \ 1514 prio 2 avpkt 1000 cell 8 weight 800Kbit split 1:0 bounded tc class add dev eth0 parent 1:1 classid 1:3 cbq bandwidth 10Mbit rate 1Mbit maxburst 20 allot \ 1514 prio 1 avpkt 1000 cell 8 weight 100Kbit split 1:0 tc class add dev eth0 parent 1:1 classid 1:4 cbq bandwidth 10Mbit rate 1Mbit maxburst 20 allot \ 1514 prio 6 avpkt 1000 cell 8 weight 100Kbit split 1:0 3) 为每一分类建立一个基于路由的过滤器;tc filter add dev eth0 parent 1:0 protocol ip prio 100 routetc filter add dev eth0 parent 1:0 protocol ip prio 100 route to 2 flowid 1:2 tc filter add dev eth0 parent 1:0 protocol ip prio 100 route to 3 flowid 1:3 tc filter add dev eth0 parent 1:0 protocol ip prio 100 route to 4 flowid 1:4 4) 最后与过滤器相配合,建立特定的路由表。ip route add 192.168.1.24 dev eth0 via 192.168.1.66 realm 2 ip route add 192.168.1.30 dev eth0 via 192.168.1.66 realm 3ip route add 192.168.1.0/24 dev eth0 via 192.168.1.66 realm 4 3 应用,监控--关于负载平衡--关于负载平衡 CONFIG_IP_ROUTE_MULTIPATH内核选项将把所有这些路径(缺省路由)等同看待,然后再根据/usr/src/linux /Documentation/Configure.help来选择其特定的方式。Ip route命令的equalize选项,会让Linux内核基于IP地址平衡外部连接。对于一个特定的IP地址,内核会选择一个接口用于传输流出的数据包,然后内核会为该IP地址在路由缓冲中建一个记录。这样,其它到达的有相同IP地址的数据包就会使用同一个接口,直到该记录从路由缓冲中删除。我们可以使用ip route list cache命令来查看路由缓冲。通过DNS循环来实现的服务的负载平衡各种不同的服务(DNS、SMTP、HTTP、LDAP、SSH等) 可以通过DNS循环来实现。循环复用DNS还有太多的限制(DNS缓存,忽略TTL值,修改后的刷新时间,不能意识到服务器的可用性),只能算是一种勉强可接受的负载平衡方案--相关命令 --ip link list 显示链路ip address show 显示IP地址 对于PPP0接口还会告诉我们链路另一端的地址ip route show 输出结果之一default via x.x.x.x dev xip neigh show 查看缓存的ARP表ip neigh delete x.x.x.x dev x--TC流量控制:--我们只能对发送数据进行整形默认整形方式是Pfifo_fast队列规定。特点为先进先出。只看数据包的TOS字节节来判断应该放到哪个频道(优先).一般的应用程序会如何设置他们的TOS值。HTB分层的令牌桶 HTB 可以保障提供给每个类带宽的数量是它所需求的最小需求或者等于分配给它的数量.当一个类需要的带宽少于分配的带宽时,剩余的带宽被分配给其他需要服务的类. SFQ随机公平队列 简单轮转。使用一个散列算法,把所有的会话映射到有限的几个队列中去。(只有当你的出口网卡确实已经挤满了的时候,SFQ才会起作用) (如果你并不希望进行流量整形,只是想看看你的网卡是否有比较高的负载而需要使用队列,可使用pfifo队列。它缺乏内部频道但是可以统计backlog)--HTB应用案例4--1)tc qdisc add dev eth0 root handle 1: htb default 12 2)tc class add dev eth0 parent 1: classid 1:1 htb rate 100kbps ceil 100kbpstc class add dev eth0 parent 1:1 classid 1:10 htb rate 30kbps ceil 100kbpstc class add dev eth0 parent 1:1 classid 1:11 htb rate 10kbps ceil 100kbpstc class add dev eth0 parent 1:1 classid 1:12 htb rate 60kbps ceil 100kbps 3)为队列规定分配子类, 如果没有指定缺省是pfifotc qdisc add dev eth0 parent 1:10 handle 20: pfifo limit 5tc qdisc add dev eth0 parent 1:11 handle 30: pfifo limit 5tc qdisc add dev eth0 parent 1:12 handle 40: sfq perturb 10 1:12队列的类不定义时,即所有不匹配其它类规则的数据包。--流量分析与故障诊断--tc -s -d qdisc show dev eth0 队列状态tc -s class show dev eth0 类状态tc filter show dev eth0 过滤器状态策略性路由
策略性是指对于IP包的路由是以网络管理员根据需要定下的一些策略为主要依据进行路由的。例如我们可以有这样的策略:“所有来直自网A的包,选择X路径;其他选择Y路径”,或者是“所有TOS为A的包选择路径F;其他选者路径K”。
Cisco 的网络操作系统 (Cisco IOS) 从11.0开始就采用新的策略性路由机制。而Linux是在内核2.1开始采用策略性路由机制的。策略性路由机制与传统的路由算法相比主要是引入了多路由表以及规则的概念。多路由表(multiple Routing Tables)
传统的路由算法是仅使用一张路由表的。但是在有些情形底下,我们是需要使用多路由表的。例如一个子网通过一个路由器与外界相连,路由器与外界有两条线路相连,其中一条的速度比较快,一条的速度比较慢。对于子网内的大多数用户来说对速度并没有特殊的要求,所以可以让他们用比较慢的路由;但是子网内有一些特殊的用户却是对速度的要求比较苛刻,所以他们需要使用速度比较快的路由。如果使用一张路由表上述要求是无法实现的,而如果根据源地址或其它参数,对不同的用户使用不同的路由表,这样就可以大大提高路由器的性能。
规则(rule)
规则是策略性的关键性的新的概念。我们可以用自然语言这样描述规则,例如我门可以指定这样的规则:
规则一:“所有来自192.16.152.24的IP包,使用路由表10, 本规则的优先级别是1500” 规则二:“所有的包,使用路由表253,本规则的优先级别是32767”我们可以看到,规则包含3个要素:
什么样的包,将应用本规则(所谓的SELECTOR,可能是filter更能反映其作用); 符合本规则的包将对其采取什么动作(ACTION),例如用那个表; 本规则的优先级别。优先级别越高的规则越先匹配(数值越小优先级别越高)。策略性路由的配置方法
传统的linux下配置路由的工具是route,而实现策略性路由配置的工具是iproute2工具包。这个软件包是由Alexey Kuznetsov开发的,软件包所在的主要网址为ftp://ftp.inr.ac.ru/ip-routing/。
这里简单介绍策略性路由的配置方法,以便能更好理解第二部分的内容。详细的使用方法请参考Alexey Kuznetsov写的 ip-cfref文档。策略性路由的配置主要包括接口地址的配置、路由的配置、规则的配置。接口地址的配置IP Addr
对于接口的配置可以用下面的命令进行:
Usage: ip addr [ add | del ] IFADDR dev STRING
router># ip addr add 192.168.0.1/24 broadcast 192.168.0.255 label eth0 dev eth0
路由的配置IP Route
Linux最多可以支持255张路由表,其中有3张表是内置的:
表255 本地路由表(Local table) 本地接口地址,广播地址,已及NAT地址都放在这个表。该路由表由系统自动维护,管理员不能直接修改。 表254 主路由表(Main table) 如果没有指明路由所属的表,所有的路由都默认都放在这个表里,一般来说,旧的路由工具(如route)所添加的路由都会加到这个表。一般是普通的路由。 表253 默认路由表 (Default table) 一般来说默认的路由都放在这张表,但是如果特别指明放的也可以是所有的网关路由。 表 0 保留路由配置命令的格式如下:
Usage: ip route list SELECTORip route { change | del | add | append | replace | monitor } ROUTE
ip route list table table_number
router># ip route add 0/0 via 192.168.0.4 table mainrouter># ip route add 192.168.3.0/24 via 192.168.0.3 table 1
在多路由表的路由体系里,所有的路由的操作,例如网路由表添加路由,或者在路由表里寻找特定的路由,需要指明要操作的路由表,所有没有指明路由表,默认是对主路由表(表254)进行操作。而在单表体系里,路由的操作是不用指明路由表的。
规则的配置IP Rule
在Linux里,总共可以定义 个优先级的规则,一个优先级别只能有一条规则,即理论上总共可以有 条规则。其中有3个规则是默认的。命令用法如下:
Usage: ip rule [ list | add | del ] SELECTOR ACTIONSELECTOR := [ from PREFIX ] [ to PREFIX ] [ tos TOS ][ dev STRING ] [ pref NUMBER ]ACTION := [ table TABLE_ID ] [ nat ADDRESS ][ prohibit | reject | unreachable ][ flowid CLASSID ]TABLE_ID := [ local | main | default | new | NUMBER
root@netmonster# ip rule list0: from all lookup local32766: from all lookup main32767: from all lookup default<code> 规则0,它是优先级别最高的规则,规则规定,所有的包,都必须首先使用local表(254)进行路由。本规则不能被更改和删除。 规则32766,规定所有的包,使用表main进行路由。本规则可以被更改和删除。 规则32767,规定所有的包,使用表default进行路由。本规则可以被更改和删除。 在默认情况下进行路由时,首先会根据规则0在本地路由表里寻找路由,如果目的地址是本网络,或是广播地址的话,在这里就可以找到合适的路由;如果路由失败,就会匹配下一个不空的规则,在这里只有32766规则,在这里将会在主路由表里寻找路由;如果失败,就会匹配32767规则,即寻找默认路由表。如果失败,路由将失败。重这里可以看出,策略性路由是往前兼容的。 还可以添加规则:<code>router># ip rule add [from 0/0] table 1 pref 32800router >#ip rule add from 192.168.3.112/32 [tos 0x10] table 2 pref 1500 prohibit
router># ip rule0: from all lookup local1500 from 192.168.3.112/32 [tos 0x10] lookup 232766: from all lookup main32767: from all lookup default32800: from all lookup 1
采取的动作除了指定表,还可以指定下面的动作:
Table 指明所使用的表 Nat 透明网关 Action prohibit 丢弃该包,并发送 COMM.ADM.PROHIITED的ICMP信息 Reject 单纯丢弃该包 Unreachable丢弃该包, 并发送 NET UNREACHABLE的ICMP信息策略性路由的应用
基于源地址选路( Source-Sensitive Routing)
如果一个网络通过两条线路接入互联网,一条是比较快的ADSL,另外一条是比较慢的普通的调制解调器。这样的话,网络管理员既可以提供无差别的路由服务,也可以根据源地址的不同,使一些特定的地址使用较快的线路,而普通用户则使用较慢的线路,即基于源址的选路。根据服务级别选路(Quality of Service)
网络管理员可以根据IP报头的服务级别域,对于不同的服务要求可以分别对待对于传送速率、吞吐量以及可靠性的有不同要求的数据报根据网络的状况进行不同的路由。节省费用的应用
网络管理员可以根据通信的状况,让一些比较大的阵发性通信使用一些带宽比较高但是比较贵的路径一段短的时间,然后让基本的通信继续使用原来比较便宜的基本线路。例如,管理员知道,某一台主机与一个特定的地址通信通常是伴随着大量的阵发性通信的,那么网络管理员可以安排一些策略,使得这些主机使用特别的路由,这些路由是按需拨号,带宽比较高的线路,通信完成以后就停止使用,而普通的通信则不受影响。这样既提高网络的性能,又能节省费用。负载平衡(Load Sharing)
根据网络交通的特征,网络管理员可以在不同的路径之间分配负荷实现负载平衡。Linux下策略性路由的实现--RPDB(Routing Policy DataBase)
在Linux下,策略性路由是由RPDB实现的。对于RPDB的内部机制的理解,可以加深对于策略性路由使用的理解。这里分析的是linux 2.4.18的RPDB实现的细节。主要的实现文件包括:
fib_hash.cfib_rules.cfib_sematicfib_frontend.croute.c
路由表(Fib Table)
数据结构:
在整个策略性路由的框架里,路由表是最重要的的数据结构,我们在上面以及对路由表的概念和结构进行了清楚的说明。Linux里通过下面这些主要的数据结构进行实现的。主要的数据结构 作用 位置struct fib_table 路由表 ip_fib.h 116struct fn_hash 路由表的哈希数据 fib_hash.c 104struct fn_zone zone域 fib_hash.c 85struct fib_node 路由节点 fib_hash.c 68struct fib_info 路由信息 ip_fib.h 57struct fib_result 路由结果 ip_fib.h 86
路由表的操作:
Linux策略路由代码的主要部分是对路由表的操作。对于路由表的操作,物理操作是直观的和易于理解的。对于表的操作不外乎就是添加、删除、更新等的操作。还有一种操作,是所谓的语义操作,语义操作主要是指诸如计算下一条的地址,把节点转换为路由项,寻找指定信息的路由等。
1、物理操作(operation):
路由表的物理操作主要包括如下这些函数:路由标操作 实现函数 位置新建路由表删除路由表搜索路由 fn_hash_lookup fib_hash.c 269插入路由到路由表 fn_hash_insert fib_hash.c 341删除路由表的路由 fn_hash_deletefn_hash_dumpfib_hash.c 433fib_hash.c 614更新路由表的路由 fn_hash_flush fib_hash.c 729显示路由表的路由信息 fn_hash_get_info fib_hash.c 750选择默认路由 fn_hash_select_default fib_hash.c 842
3、接口(front end)
对于路由表接口的理解,关键在于理解那里有IP
首先是路由表于IP层的接口。路由在目前linux的意义上来说,最主要的还是IP层的路由,所以和IP层的的接口是最主要的接口。和ip层的衔接主要是向IP层提供寻找路由、路由控制、寻找指定ip的接口。Fil_lookupip_rt_ioctl fib_frontend.c 286;" fip_dev_find 145
inet_rtm_delroute 351inet_rtm_newroute 366inet_check_attr 335
4、网络设备(net dev event)
路由是和硬件关联的,当网络设备启动或关闭的时候,必须通知路由表的管理程序,更新路由表的信息。fib_disable_ip 567fib_inetaddr_event 575fib_netdev_event
fib_magic 417fib_add_ifaddr 459fib_del_ifaddr 498
Rule
1、数据结构
规则在fib_rules.c的52行里定义为 struct fib_rule。而RPDB里所有的路由是保存在101行的变量fib_rules里的,注意这个变量很关键,它掌管着所有的规则,规则的添加和删除都是对这个变量进行的。2、系统定义规则:
fib_rules被定义以后被赋予了三条默认的规则:默认规则,本地规则以及主规则。u 本地规则local_rule94 static struct fib_rule local_rule = { r_next: &main_rule, /*下一条规则是主规则*/r_clntref: ATOMIC_INIT(2),r_table: RT_TABLE_LOCAL, /*指向本地路由表*/r_action: RTN_UNICAST, /*动作是返回路由*/};
u 主规则main_rule86 static struct fib_rule main_rule = { r_next: &default_rule,/*下一条规则是默认规则*/r_clntref: ATOMIC_INIT(2),r_preference: 0x7FFE, /*默认规则的优先级32766*/r_table: RT_TABLE_MAIN, /*指向主路由表*/r_action: RTN_UNICAST, /*动作是返回路由*/};
u 默认规则default rule79 static struct fib_rule default_rule = { r_clntref: ATOMIC_INIT(2),r_preference: 0x7FFF,/*默认规则的优先级32767*/r_table: RT_TABLE_DEFAULT,/*指默认路由表*/r_action: RTN_UNICAST,/*动作是返回路由*/};
RPDB的中心函数fib_lookup
现在到了讨论RPDB的实现的的中心函数fib_lookup了。RPDB通过提供接口函数fib_lookup,作为寻找路由的入口点,在这里有必要详细讨论这个函数,下面是源代码:
310 int fib_lookup(const struct rt_key *key, struct fib_result *res)311 { 312 int err;313 struct fib_rule *r, *policy;314 struct fib_table *tb;315316 u32 daddr = key->dst;317 u32 saddr = key->src;318321 read_lock(&fib_rules_lock);322 for (r = fib_rules; r; r=r->r_next) {/*扫描规则链fib_rules里的每一条规则直到匹配为止*/323 if (((saddr^r->r_src) & r->r_srcmask) ||324 ((daddr^r->r_dst) & r->r_dstmask) ||325 #ifdef CONFIG_IP_ROUTE_TOS326 (r->r_tos && r->r_tos != key->tos) ||327 #endif328 #ifdef CONFIG_IP_ROUTE_FWMARK329 (r->r_fwmark && r->r_fwmark != key->fwmark) ||330 #endif331 (r->r_ifindex && r->r_ifindex != key->iif))332 continue;/*以上为判断规则是否匹配,如果不匹配则扫描下一条规则,否则继续*/335 switch (r->r_action) {/*好了,开始处理动作了*/336 case RTN_UNICAST:/*没有设置动作*/337 case RTN_NAT: /*动作nat ADDRESS*/338 policy = r;339 break;340 case RTN_UNREACHABLE: /*动作unreachable*/341 read_unlock(&fib_rules_lock);342 return -ENETUNREACH;343 default:344 case RTN_BLACKHOLE:/* 动作reject */345 read_unlock(&fib_rules_lock);346 return -EINVAL;347 case RTN_PROHIBIT:/* 动作prohibit */348 read_unlock(&fib_rules_lock);349 return -EACCES;350 }351 /*选择路由表*/352 if ((tb = fib_get_table(r->r_table)) == NULL)353 continue;/*在路由表里寻找指定的路由*/354 err = tb->tb_lookup(tb, key, res);355 if (err == 0) {/*命中目标*/356 res->r = policy;357 if (policy)358 atomic_inc(&policy->r_clntref);359 read_unlock(&fib_rules_lock);360 return 0;361 }362 if (err < 0 && err != -EAGAIN) {/*路由失败*/363 read_unlock(&fib_rules_lock);364 return err;365 }366 }368 read_unlock(&fib_rules_lock);369 return -ENETUNREACH;370 }
IP层路由适配(IP route)
路由表以及规则组成的系统,可以完成路由的管理以及查找的工作,但是为了使得IP层的路由工作更加的高效,linux的路由体系里,route.c里完成大多数IP层与RPDB的适配工作,以及路由缓冲(route cache)的功能。
调用接口
IP层的路由接口分为发送路由接口以及接收路由接口:
发送路由接口
IP层在发送数据时如果需要进行路由工作的时候,就会调用ip_route_out函数。这个函数在完成一些键值的简单转换以后,就会调用 ip_route_output_key函数,这个函数首先在缓存里寻找路由,如果失败就会调用 ip_route_output_slow,ip_route_output_slow里调用fib_lookup在路由表里寻找路由,如果命中,首先在缓存里添加这个路由,然后返回结果。
ip_route_out route.hip_route_output_key route.c 1984;ip_route_output_slow route.c 1690;"
接收路由接口
IP层接到一个数据包以后,如果需要进行路由,就调用函数ip_route_input,ip_route_input现在缓存里寻找,如果失败则 ip_route_inpu调用ip_route_input_slow, ip_route_input_slow里调用fib_lookup在路由表里寻找路由,如果命中,首先在缓存里添加这个路由,然后返回结果。
ip_route_input_slow route.c 1312;" fip_route_input route.c 1622;" f
cache
路由缓存保存的是最近使用的路由。当IP在路由表进行路由以后,如果命中就会在路由缓存里增加该路由。同时系统还会定时检查路由缓存里的项目是否失效,如果失效则清除。
Linux高级路由技术-实现双线服务器
三19背景:两个网卡,两条线路:电信和网通
以前:
/eth0 3.3.3.2 ——> 3.3.3.1 router1server \eth1 4.4.4.2 ——> 4.4.4.1 router2 eth0 3.3.3.2 eth1 4.4.4.2 共用一个网关: 3.3.3.1 缺点:只能有一个网关,无法智能判断线路来源。实验拓扑图
/eth0 —– eth0[Router_1]eth1 —– eth0\Client Server \eth1 —– eth0[Router_2]eth1 —– eth1/Client eth0 1.1.1.2 vmnet1 eth1 2.2.2.2 vmnet2Router_1
eth0 1.1.1.1 vmnet1 eth1 3.3.3.1 vmnet3Router_2
eth0 2.2.2.1 vmnet2 eth1 4.4.4.1 vmnet4Server
eth0 3.3.3.2 vmnet3 eth1 4.4.4.2 vmnet4需要运行vmware-config.pl增加这些虚拟网卡,类型为hostonly一、Server配置: # ifconfig eth0 3.3.3.2 netmask 255.255.255.0# ifconfig eth1 4.4.4.2 netmask 255.255.255.0设定前路由表
# ip route4.4.4.0/24 dev eth1 proto kernel scope link src 4.4.4.23.3.3.0/24 dev eth0 proto kernel scope link src 3.3.3.210.1.1.0/24 dev eth2 proto kernel scope link src 10.1.1.138169.254.0.0/16 dev eth2 scope linkdefault via 10.1.1.1 dev eth2 <—所有网卡公用一个网关思路:是为两个网卡建立独立的路由表,他们有自己的网关
1、额外添加两个路由表# ip route add 3.3.3.0 dev eth0 src 3.3.3.2 table 1 <—新建路由条目,关于3.3.3.0网络的,放到一个编号为1的路由表# ip route add default via 3.3.3.1 table 1 <—为路由表 1 增加一个默认网关# ip route list table 13.3.3.0 dev eth0 scope link src 3.3.3.2default via 3.3.3.1 dev eth0# ip route add 4.4.4.0 dev eth1 src 4.4.4.2 table 2# ip route add default via 4.4.4.1 table 2# ip route list table 24.4.4.0 dev eth1 scope link src 4.4.4.2default via 4.4.4.1 dev eth12、设定main主路由表(ip route 看到的路由表)
# ip route add 3.3.3.0 dev eth0 src 3.3.3.2
# ip route add 4.4.4.0 dev eth1 src 4.4.4.23、设定默认路由
作用:给自己主动发数据包的时候选择一个默认的网关如果原来存在默认网关,而不是你想设定的那个,那么先删除
# ip route del default via 10.1.1.1# ip route add default via 3.3.3.1
4、设定路由规则,保证数据包从原网卡回去# ip rule add from 3.3.3.2 table 1 <— from 指定数据包的源IP <— 如果数据包的源IP是3.3.3.2,那么就使用路由表1里路由条目对数据包进行路由# ip rule add from 4.4.4.2 table 2
路由器的配置:
1、打开路由转发 2、配置IP客户端配置:
1、配置IP 2、网关根据实验改变验证:A:1、把客户端的默认网关设置为1.1.1.1 ,模拟电信线路2、ping 3.3.3.2 <–Server电信线路的IP3、捉包在router_1: tcpdump icmp -n -i eth1在router_2: tcpdump icmp -n -i eth1B:
1、把客户端的默认网关设置为2.2.2.1 ,模拟电信线路2、ping 4.4.4.2 <–Server网通线路的IP3、捉包在router_1: tcpdump icmp -n -i eth1在router_2: tcpdump icmp -n -i eth1linux路由工具:iproute2/iptables(路由配置实例)
2013-06-23 19:07:01| 分类: 路由负载均衡 | 标签:路由方案 linuxk路由技术 |举报|字号 订阅
1、ip route add 和 ip rule add to之间的区别
ip route add 是往main表中增加目的地址路由表项.ip route add*****此处只能以源地址来区分路由;
ip rule add to,往指定表增加目的地址路由表项. 我们可以建多个表,可以以目标地址区分路由;ip rule add from,往指定表中增加源地址路由表项 ;2、Linux下基于路由策略的IP地址控制实例
一、背景描述
LINUX是一台网关服务器,内有3块网卡。
eth1绑定172.17.0.0/16的IP,该网段IP可以通过172.17.1.1上网。
eth0绑定192.168.10.0/24的IP,该网段IP可以通过192.168.10.1上网。
eth2绑定192.168.1.1,是内网用户的网关。
二、需求分析
内网用户应该走172.17.1.1这个路由上网。
但由于工作需要,部分用户应该有访问图中“专用网络”的权限。
也就是说,应该走192.168.10.1这个路由。
另外一点,所有人应该可以访问FTP服务器,这个服务器的IP是192.168.10.96
也就是说,走172.17.1.1路由的人,也应该能访问192.168.10.96,且可以上网。
三、解决方案
要解决这个问题,用到了一下几个命令,具体使用方法需要另查资料。
ip route
ip rule
arp
注:关于ip命令的用法,请查阅ip中文手册。
1、绑定IP
ifconfig eth1 172.17.3.x netmask 255.255.0.0
ifconfig eth0 192.168.10.2 netmask 255.255.255.0
ifconfig eth2 192.168.1.1 netmask 255.255.255.0
然后分别修改/etc/sysconfig/network-script/ifcfg-ethx文件,以使计算机启动自动设置IP地址。
在ubuntu下,使用interfaces来定义;
2、创建特殊路由表(手中创建)
vi /etc/iproute2/rt_table
代码:
#
# reserved values
#
255 local
254 main
253 default
0 unspec
200 NET10
#
# local
#
#1 inr.ruhep
上面那个200 NET10为新添加,自定义编号为200,名字为NET10
3、向NET10路由中添加它自己的默认路由。
代码:
ip route add default via 192.168.10.1 table NET10
注意,这个table NET10一定不要忘了写,否则写到了主路由表中。
4、创建特殊路由规则
用ip rule可以看到计算机当前的路由规则。
引用:
0: from all lookup local
32766: from all lookup main
32767: from all lookup default
可以看到,规则中走了3个路由表,local、main、default
我们平常用route看到的,实际是路由表main
这些规则是按序号大小顺序走的,一个不同,则走下一个,知道通路或走完为止。
开始添加我们自己的路由NET10到路由表中。
代码:
ip rule add from 192.168.1.222 pref 10000 table NET10
这个意思是说,如果来自IP地址为192.168.1.222的访问,则启用NET10的路由表中的路由规则。
而NET10的路由规则是什么呢?上面已经设置了,走的是192.168.10.1的网段。
接下来,使LINUX可以NAT(这里不再细说HOW TO了)
5、让所有人可以访问192.168.10.xx(这个IP不便说出来)
因为其余人都走了172.17.1.1这个路由,所以他们是无法访问192.168.10.xx的 。
怎么才能实现呢?再添加个策略就可以了!
代码:
ip rule add to 192.168.10.xx pref 10001 table NET10
这句话的意思是说,所有人,如果目的IP是192.168.10.xx,则临时使用NET10的路由表。
这样做,安全会不会有安全问题呢?路由变了,他们会不会访问到专用网络呢?
不会的,因为路由规则是to 192.168.10.xx,也就是目标是96时,才该路由的,访问别的网站还是走原来的路由。
如果说访问到专用网络的机器,也就只有10.xx这一台而已。
这里,我们还可以做一个小技巧,不告诉别人192.168.10.xx的地址,只告诉他们网关192.168.1.1上有这个服务
iptables -t nat -A PREROUTING -d 192.168.1.1/32 --dport 21 -j DNAT --to 192.168.10.xx:21
6、防止其他人篡改IP地址而获得特殊权限
arp有个静态功能CM,不是C,大家可能知道。
如果给一个IP地址强行绑定一个非他自己的MAC,会怎么样呢?双方会话将会失败!
好,我们来利用这一点!
首先,我写了一个文件iproute.c
代码:
#include
#include
main ()
{
int i;
for(i=2;i<255;i++)
printf("192.168.1.%d\t\t00:00:00:00:00:00\n",i);
}
gcc iproute.c -o iproute
将编译出一个可执行文件
注:不应该包括主机IP地址本身,所以从2循环到254(255是广播)
其次,生成一个C的IP地址和全为00的MAC地址。
代码:
./iproute > /etc/ethers
再次,修改IP-MAC匹配列表。
vi /etc/ethers
具体怎么该我就不用细说了,相信大家都会。
最后,做静态IP-MAC绑定。
arp -f
7、为了安全,建立防火墙,修改main路由表
默认的路由表应该有192.168.10.0/24和172.17.0.0/16网段的内容,为了安全,可以去掉。
参考实例:
ip route add 58.14.0.0/15 via 192.168.33.1 table cnline
此处会新建路由表cnline;
ip route add 58.16.0.0/16 via 192.168.33.1 table cnlineip route del default #操作的是路由表main; ip route add default via 192.168.33.1 #也给主路由表main加上了cnline相同的网关,单网卡情况,只能如此,多网卡即可出于不同网卡了,使用ebtables也可以实现类似功能; ip rule add from 192.168.2.6 pref 1000 lookup cnline #表示主机源192.168.2.6的请求都去cnline表的规定路由; ip rule add from 192.168.2.4 pref 1000 lookup cnline ip rule add from 192.168.2.32 pref 1000 lookup cnline ip rule add to 10.10.10.189 pref 1000 lookup cnline #即去目标地址为10.10.10.189的数据包也在cnline中找出路;其中lookup可以省去,不过笔者喜欢写着,意义更明确。